↧
Fedora 10について
↧
そろそろクリックジャッキングについて一言いっておくか
Firefox3で「サードパーティのCookieも保存する」をオフにする。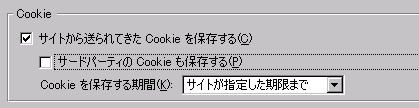
防げる。
いずれのブラウザにもサードパーティ製のcookieを制限するオプションがあるが、Firefox3以外だと、フレーム内表示された場合に「新規にcookieを保存しない」だけで保存済みのcookieは送信してしまう。
軽く調べてみたところ、次のようになった。(間違ってたら教えてください)
| サードパーティのcookieの新規保存 | サードパーティの保存済みcookieの送信 | 表示中のドメインのcookieの保存/送信 | |
|---|---|---|---|
| IE6,7,8(デフォルト) | x | o | o |
| IE6,7,8(セキュリティ高) | x | x | x |
| Opera9.6(デフォルト) | o | o | o |
| Opera9.6(制限) | x | △ | o |
| Safari(制限/デフォルト) | x | o | o |
| Safari(全て受け入れる) | o | o | o |
| Firefox2(デフォルト) | o | o | o |
| Firefox2(ブロック) | x | x | x |
| Firefox3(デフォルト) | o | o | o |
| Firefox3(制限) | x | x | o |
oは送られた。xは送られなかった。Operaが△なのは画面遷移したら、cookieが送られてしまったため。
個人的な見解だけれども、ブラウザはアドレスバーに表示されているドメイン以外へのcookieの送信を(ユーザーが明示的に許可しない限り)やめるべきだし、それが適切なデフォルトだと思う。サイト側のJavaScriptでフレーム拒否とか、JavaScript有効になってる前提だし、(現実的な対策ではあるけれども)本質的な対策ではないでしょう。外部ドメインへのcookieの送信が無効であれば、クリックジャッキングで可能な攻撃は大幅に制限される。認証が不要な掲示板に自動で犯行予告を投稿させてIPアドレスをログに残させるぐらいだ。(それはクリックジャッキングを使わなくても出来る)
サードパーティへのcookieの送信が制限されても、外部サイトへのcookieの送信を前提としているサービス*1が使えなくなるぐらいだ。フレーム禁止しないと、本物のサイトに攻撃者のサイトを重ね合わせる手法が防げないけれど、それに引っかかる人間は元々フィッシング詐欺に引っかかる。*2
X-FRAME-OPTIONSのような、サイト側からの意思表示が出来る仕組みを作るのであれば「外部サイトに埋め込まれた場合は決してcookieを送信しないでください」があってもいいんじゃないかなあ、と思います。
↧
↧
「サードパーティのCookieも保存する」をオフにするとGM_xmlhttpRequestでCookieを送らない
先日のエントリでAutoPagerizeが動かなくなったという人が居たので調べた。
同一ドメインならAutoPagerize側でどんなCookie送ってるか分かるので、とりあえずこれで動くようになった。
var headers = {}if (isSameDomain(this.requestURL)) { headers.Cookie = document.cookie }var opt = { method: 'get', url: this.requestURL, headers: headers, overrideMimeType: mime, onerror: this.error, onload: function(res){self.requestLoad.apply(self, [res]) }}
↧
美人時計の画像ファイルをグリッチしたい!
id:youpyによるGlitchMonkeyというuserscriptがあるのですが、ページ表示後に挿入された画像ファイルに関してはグリッチされないので、DOMNodeInsertedを使って対応してみました。
http://gist.github.com/77891
DOMノードが挿入される度に美人時計の画像ファイルをダウンロードして正規表現による置換を行ってグリッチされます。

↧
ルネッサンス吉田 茜新地花屋散華
")
- 作者:ルネッサンス吉田
- 出版社/メーカー:茜新社
- 発売日: 2009/03/27
- メディア:コミック
- 購入: 10人 クリック: 97回
- この商品を含むブログ (32件) を見る
「余録・うなぎまつり」単行本描き下ろし
好きな作家さんが「うなぎには暗いところに潜り込む習性があるんだよ」と教えてくれたのでそれはとてもいい話だと思って書きました。
↧
↧
楽天のサポートに問い合わせた
楽天で商品購入の際に出店者にメールアドレスが通知されるのかということが純粋に気になったので、客として楽天のサポートに問い合わせました。
文面はこんな感じです。
http://gyazo.com/12bdebc38f8412d776836fb5c983a11e.png
まともな回答が得られなければ出店者側に聞いてみるつもりでしたが、サポート担当者からはっきりとした回答が得られました。
お問い合わせの件で、ご心配をおかけしております。
この度、「Gigazine」で掲載されておりました「楽天、利用者の
メールアドレスを含む個人情報を1件10円でダウンロード販売」は
全くの事実誤認でございます。(中略)
注文のステップ4で表示されておりますお客様の情報
(お名前、メールアドレス、フリガナ、住所、電話番号等)が
[この内容で注文する]のボタンをご利用いただいた時点で、
該当のショップへ送信されます。何とぞ、ご了承いただきますようお願いいたします。
弊社は楽天の個人情報保護方針にもとづいて
個人情報の取扱いに関して万全の管理体制を敷いておりますので、
お客様におかれましては、今後とも安心してお買い物をお楽しみ下さい。
GIGAZINEの件については聞いてないんですけども、注文の際には該当のショップに「お名前、メールアドレス、フリガナ、住所、電話番号等」が送信されるという回答を得られました。「メールアドレスを秘匿できるようにするシステムの実施」については回答がありませんでした。
そんなわけですから楽天市場で注文をする際に、出店者にメールアドレスは送信されます。実際のところ、楽天にはチンポatマラじゃなくてもう少しマシなメールアドレスで登録してあるんですけど、いずれにせよメールアドレスにマラとか入ってるのが倫理的に考えて良いわけが無いですし、yumichan_love_foreverとかそんな感じの痛いメールアドレス使ってる人は注意した方が良いと思いますよ。
INTERNET Watchの記事について
http://internet.watch.impress.co.jp/cda/news/2009/05/28/23591.html
楽天はINTERNET Watchの取材に対して、「現在もクレジットカード情報とメールアドレスを店舗に渡していない」と説明する
(中略)
また、楽天が審査をした上で利用者のメールアドレスを提供していること関しては、「個人情報保護方針に沿ったかたちで、正当な理由と判断された場合は提供することもある」とコメント。ただし、楽天が認める「正当な理由」については、機密なので明かせないという。
要約すると
- (原則として) メールアドレスを店舗に渡していない
- (例外的に) 正当な理由と判断された場合は提供することもある(条件は機密)
という内容ですよね。機密なので明かせないと書いてあるので勝手な想像をする方が悪いのかも知れませんが、記事中にGIGAZINEでの報道内容が引用されており、
ただし、月間売り上げ1000万円以上または月間受注件数1000件以上の店舗であれば、メールアドレスについては、楽天の審査に通過した上で、メールアドレスを外部に提供しない旨などを記した誓約書を提出すれば取得できる。
と書かれているため「月間売り上げ1000万円以上または月間受注件数1000件以上で楽天の審査に通過して誓約書を書けばメールアドレスが提供される」と勘違いしている人が多いんじゃないですかね。(実際にそういう勘違いをしたので楽天に問い合わせました)
しかしながら、サポートに問い合わせた内容と照らし合わせて推測するに、楽天が機密なので明かせないと主張するメールアドレスを提供する「正当な理由」というのは「ショップで買い物をすること」です。INTERNET Watchはろくな検証もせずに楽天の言い分をそのまま載せただけで、読者に誤解を与える記事を掲載しているのですから、追記するなり訂正記事を出すなりして、きちんとメディアとしての責務を果たすべきだと思いますよ。
誇張表現について
GIGAZINEのメディアとしての信憑性が下がりすぎていて、皆さん公正な判断が出来なくなってるんじゃないですか。
いずれも誇張表現ですけど楽天のケースの方が悪質だと思います。GIGAZINEの記事は記事タイトルが全力釣りなだけで、spam業者に全アドレスを1件10円で販売なんて書いてないですし、長すぎて読む人がいないってだけで本文中に条件や対象範囲が書かれてますよね。対して楽天の主張は、記事本文を見たって条件が分からないんですし、規約を見てもはっきりしません。
楽天オフィシャルからのお知らせなんて事実誤認としか書いてないですし。
http://www.rakuten.co.jp/help/whatsnew/
これだけ誤解を招く情報がネット上に錯綜しているのに楽天の広報って何の仕事してるんですかね!
はてなでアンケートを取った
http://q.hatena.ne.jp/1243598560
こういう書き込みした後で
http://twitter.com/bulkneets/status/1958479429
http://twitter.com/bulkneets/status/1958885128
twitterから誘導してしまったのでバイアスはかかってると思いますが、このアンケートの結果では、ショップにメールアドレスが知られないと思っている人が20%は居るということになりました。結構な割合の人が「ショップにメールアドレスが知られないと思って買い物をしている」のではないかと想像されます。繰り返しになりますが、チンポatマラとかyumichan_love_foreverとかそんな感じの痛いメールアドレス使ってる人は注意した方が良いと思いますよ。
メールフォワーディング機能について
2005年の時点で、「メールフォワーディング機能」「メールアドレス匿名サービス」というふうに言われる機能が提供される予定だと楽天からのリリースがあります。
http://itpro.nikkeibp.co.jp/free/NCC/NEWS/20050801/165646/
サポートに対する質問で、この部分を華麗にスルーされてしまったのですが、その後のリリースも無いし、現時点では導入されていないと考えるのが自然だと思います。
信頼できるかどうか分かりませんが、出店者向けのリリース情報が転載されています。
http://jbbs.livedoor.jp/bbs/read.cgi/shop/960/1122130979/151
http://jbbs.livedoor.jp/bbs/read.cgi/shop/960/1122130979/157
利用規約には「その取引に必要な範囲で、お客様の個人データをサービス提供者に提供します。」というのがあって、
http://privacy.rakuten.co.jp/#5
問題になりそうなのって、その取引に必要な範囲にメールアドレスが含まれるのかどうかということですよね。利用規約の解釈としては連絡手段として必要ってことになるんでしょうけども、楽天が出店者と注文者のメールアドレスを知ってるんだから、取り引きの間だけ有効 or その店舗からしか送れない転送メールアドレスを作ってやればいい話で、そういう予定だったのだけども、未だに開発できていないか、開発コストと個人情報流出のリスクを天秤に掛けて見合わないと判断されたとか、店側からの反発があったとか、そんなんで未だに実現できていないのではないですかね。元々店舗側は個人情報の目的外利用を禁止されているはずですし生メールアドレスだろうと転送アドレスだろうと関係ないはずで、商取引に生メールアドレスが必須かどうかとか、そういうくだらないことで言い争うのは、技術者をバカにしてんのかと思いますね。全員死ね。
http://q.hatena.ne.jp/1243598560
このアンケートでは、74%の人が、出店者がメールアドレスを知る必要はないと考えています。
まとめ
- サポートに問い合わせたら聞いてもいないことを答える & 聞いてることに答えないのコンボ。
- 注文した際には店にメールアドレスは送信される。利用規約とは矛盾してないが、20%の人が知られないと思っている(はてなアンケート調べ)
- 出店者がメールアドレスを知る必要がないと考えている人が74%いる(はてなアンケート調べ)
- INTERNET Watchの記事は誤解を招きやすいので、追記するか訂正記事を出せ。
- 技術的に可能か不可能かだけが重要だし、根拠もないのに安心してくださいとかナメてんのか。
- 楽天に出店している店舗が商品注文の際に知ったメールアドレスをspam業者に横流しすることは契約上不可能でしょうけど、技術的に可能ですよね。
- だから信頼していないし、安心して買い物をしてはない。米は買うけど。
- 楽天に登録しているメールアドレスは変えようと思う。
↧
楽天が抱えている問題点その11


↧
オープンソースでない物がオープンソースと呼ばれてきた歴史まとめ
http://twitter.com/mhatta/status/2241748771
そんなのどうでもいいじゃないか。困るのは、オープンソース・ライセンスの下で公開されてないものがオープンソースと呼ばれる、ただその一点だけですよ。それさえなければ後はどうでもいいですよ。
↓
http://d.hatena.ne.jp/ktdisk/20090524/1243154905
http://d.hatena.ne.jp/n_euler666/20070723/1185117376
http://cocoa.2ch.net/unix/kako/1000/10004/1000484092.html
↧
ネットで実名を出せないサラリーマンの皆さんへ
「くっ、俺だって本当は実名で活動したい、だが会社に禁止されていて出来ないんだ、そういう人間の気持ちも考えろ!」
みたいなことを言ってしまう人は、やっぱり会社の奴隷なんじゃないかと思います。
- 会社の業務を実名ですることを強制される
- 営業で実名入りの名刺配ったり、社員紹介ページに実名顔写真セットで掲載されたり。
- 実名出しただけで会社名と紐づけられる状況が発生する
- 個人の活動を会社の活動と紐づけることを禁止する
という合わせ技で「実名で業務外の活動をすることが制限される」ってことになって、つまり「ネットで実名出せない」という現象が起こります。それを平然と受け入れちゃうのがオカシイんですよ。貴方は人権を侵害されているし、そんなのが当たり前の世の中になったら俺も困るからお前も戦え。
会社が禁止してるのか個人が自重してるのか知らないですが、一般に就業規則に書かれるのは、会社に不利な情報発信すんなとか社名出して副業すんなとか犯罪起こすなとか、そんなのでしょうから「ネットで実名出すな」なんてのは現場レベルの判断でしょう。本当にそんな会社があるのかどうか知らないですし、仮想敵かもしれません。
例えば貴方のハンドルネームがパンチラ太郎であったとして、3歳になる娘の心臓手術のためにネットで募金を集めようとするとしましょう。会社に「実名でネットするな」と禁止されている貴方は、パンチラ太郎で娘のために募金を集めようとしますが、残念ながらパンチラ太郎では不特定多数の人間の信用を得ることは難しいでしょう。あなたは娘の命を救えない。人は時としてネットで実名を出して戦わなくてはいけないときがあるんだ!貴方は会社から重大な権利を奪われている!何で戦わないんだ!!
単に就業時間内に私用でネット利用してるのがバレると困るとかいう人は、どっちにしろバレてるんで、いつでも無能なお前のクビを切れる口実を経営者に与えているだけだ!!転職や独立に有利になるようにどうせなら実名で行動しておけ!!!
僕はどうしているかというと、会社の業務をハンドルネームで行うという方向で戦っています。
↧
↧
Google Buzzで意図せず本名公開される箇所がある件
「ちゃんと警告出てただろ、注意すれば防げるんだよ情弱が」派と戦争だよ!!!!!!
実験してみた
- 「非公開の 本名」という名前でGmailアカウントを取る
- 知らない人のGoogleプロフィール(例: http://www.google.com/profiles/bulkneets )を開く
- なんか面白そうだな、フォローしてみよう
別アカウントから見た場合は隠れてるけど
bulkneetsさんから見た場合こうなる。
そんなわけだから本名設定されてるGoogleアカウントでフォローボタンを押すだけで、少なくともbulkneetsさんには非公開の本名が公開されてるけど、なんの警告も出てないですよ。
例えばGmailで「本名が表示されないように」メール送信者の名前を変えるのはGmailの設定から出来るけど、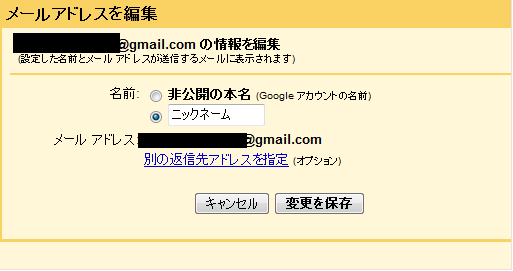
本名バレないようにGmail使ってたのに、Google Buzzの自動フォロー機能やオススメユーザーポチポチしてたら本名バレた!!みたいな人が居そうだなー。Amazonウィッシュリストの時なんかでもそうだけど、明らかにユーザーインターフェースに欠陥があるのに「注意すれば防げる」みたいな無茶なことを言うのは止めましょう。お前らこそが情弱だ!!くたばれ!!!!!!!!!
↧
XSSとセキュリティリスクと正しい脆弱性報告のあり方
適当
XSSがある=なんでもやり放題ではない
ブログサービスなど自由にHTMLをかけるようなサービスでは、害が及ばないように表示を丸ごと別のドメインに分けていたり、あるいは別ドメインのIFRAME内で実行したりしているのが普通です。個人情報を預かってるサイトは、重要個人情報についてはHTTPSじゃないと参照できなかったり、そもそも表示しなかったり(パスワードやカード番号等)、決済用のパスワードや暗証番号を入れないと操作できなかったりする。
参考までに
- http://blog.bulknews.net/mt/archives/001274.html (2004年のアメブロ脆弱性の話)
- http://d.hatena.ne.jp/yamaz/20090114 (信頼できないデータを取り扱うドメインを分ける話)
管理用と別ドメインに分けたにも関わらず、script実行できることに対してDISられている例がこちら。
- http://d.hatena.ne.jp/rosylilly/20091216/1260961264
- http://d.hatena.ne.jp/rosylilly/20091219/1261254527
scriptが書ければブラクラを置いて閲覧者に対して嫌がらせすることは出来るし、ブラウザやpluginに脆弱性がある場合「scriptを書けること自体」が深刻な脅威になりうるので、scriptを一切書けないようにするというポリシーも勿論ある。同じ会社が運営しているサービスでもドメインごとにセキュリティポリシーがある。たとえばはてなダイアリだったら、ユーザーの入力したscriptは実行不可、Google AdSenseや一部のブログパーツのスクリプトは実行されて良い、といった具合に決まってる。単にscriptが実行できるというだけで「あのサービスはXSS脆弱性がある、危険だ」と騒ぎ立てるのは良くないことだと思う。
脆弱性があった場合の影響範囲を抑える
- もし初心者がウェブアプリケーションを作るのであれば、まず最初に「脆弱性があっても大丈夫にする」ことを覚えるのが良いと思う。
- さまざまな攻撃手段や、それに対する対策方法を網羅的に学習するのは時間がかかるし、長年運営しているサイトにも放置されている脆弱性があったりする。
- 個人情報を預からないようにするとか、決済機能は外部サイトに頼るとか。
単純な例を言うと「重要な機能にはパスワードの再確認を入れる」ことだ。重要な機能は例えば、パスワードの変更、メールアドレスの変更、サービスの退会などだ。これらの機能にパスワードの再確認が無い場合、XSSが一つあるだけで、アカウントを乗っ取ったり、サービスを退会したり出来てしまう。(パスワード再確認はCSRF対策にもなる)
正しい脆弱性報告のあり方
IPAを通したりすると、対応が遅くなるのが普通です。IPAを通じて脆弱性の報告が来るということは、脆弱性の発見者がセキュリティ専門家だったりするため、対策が取られるまで公開されないことが予測できる。つまりIPAから脆弱性の報告が来る=緊急ではないという図式が成り立ってしまう!!
早急に脆弱性が修正されることを望んでいるのであれば「俺はゼロデイXSSのURLをtwitterに晒したくてウズウズしてるんだよォォォ!!!!」という姿勢を見せながら中の人に連絡するのが良いでしょう。大体その日のうちに何とかしてくれるはずです。
脆弱性の報告はIPA通すと諸々の手続きが面倒くさくなることを知っているため、サービス開発者同士のネットワークでは、IRC、各種IM、Skypeなどで中の人に直接知らせるのが普通です。そして脆弱性の報告を受けたら、お礼として焼肉や寿司を奢るという慣習がある。
ところが京都に本社を置くHという会社は、脆弱性報告の謝礼を「はてなポイント」や「カラースター」で代用するという風習があるため、必然的に脆弱性を報告するメリットが少なくなる。これは非常に危険な状態であるため、猛省を促したい。
↧
Google ToolbarやGoogle Chromeで秘密のURLが漏れるといった話
http://d.hatena.ne.jp/m-bird/20100402/1270190863とか http://anond.hatelabo.jp/20100403084111とか
ずいぶん適当なこと書いてあるなと思ったので調べた。
見ているページのURLが送られるかという話
ツールバーは使ってないのでChromeについてだけ軽く検証したので書いておく。検証したバージョンはGoogle Chrome 5.0.366.2 devでモニタに使ったのはFiddler。
見ているページのURLを自動で送信する機能はChrome自体には無い。アドレスバーにURLを貼りつければ検索語句の補完機能が動いて送られることがある。
ただしhttpsの場合はホスト名まで、httpの場合はクエリストリング(URLの?以降)は含まれない。
フォームの自動入力を有効にしたらなんかXMLが送られるけど、これは見てるページのURLは含まれない。フォーム構造のシグネチャを作って送信しているようだ。
http://www.google.com/support/toolbar/bin/answer.py?answer=81841
オートフィル機能はウェブ フォームに自動入力するオプション機能であり、これを有効にした場合は、ウェブ フォームを含むページの構造に関する限定された情報やフォームの配置に関する情報などがツールバーから Googleに送信され、Googleでそのページのオートフィル機能を改善するために利用されます。ツールバーから送信される情報には、フォームに入力したデータが含まれることがありますが、ツールバーの同期機能を使用してデータをアカウントとともに保存するよう設定している場合を除き、各欄に入力した実際のテキストが Googleに送信されることはありません。
フィッシングサイト対策もオフラインで検証していて、見ているページのURLは送らない。 http://www.google.com/support/chrome/bin/answer.py?answer=99020
クラッシュレポートと使用統計データについては調べてない。 http://www.google.com/support/chrome/bin/answer.py?answer=96817
Google ToolbarでもhttpsのURLとクエリストリングはそもそも送られないように配慮されてる。
追記: IE用Google ToolbarのVersion: 6.4.1321.1732について調べた。現在はhttpsのページのホスト名まで送るようになっている。クエリストリングは以前と変わらず送らない。
そんなわけなので、メッセサンオーの話に限って言えば「クエリストリングにパスワードを含むhttpsのURL」はGoogle ToolbarでもGoogle Chromeでも送信されない。
ただし「クエリストリングにパスワードを含むhttpsのURL」に対してリンクが貼られたhttpのURLについては自動送信される可能性があるよ。
もちろん見てるページのURLを信頼出来ない経路で自動で送るような拡張機能もある。
送信されたURLが適切に取り扱われるかという話
「送信された情報が適切に取り扱われているかどうか」については、サーバーサイドの話なんで想像で何を言われても仕方ないとは思うけど、クロールされるかどうかは外部の人間からも検証することが出来る。
第三者から検証できるので「プライバシーに配慮しない方法で未発見のURLを見つけてクロールする」のはリスクが高い。
実際にGoogle ToolbarのPageRank機能を有効にしたうえで秘密のURLにアクセスしてGoogleにインデックスされるかという実験が行われて、それに対するGoogleの中の人のコメントがある。
- http://www.sem-r.com/20/20061211122827.html
- http://blogoscoped.com/archive/2006-12-10-n75.html
- http://www.mattcutts.com/blog/debunking-toolbar-doesnt-lead-to-page-being-indexed/
普通に考えてリスクが高い。俺ならやらない。眠いし寝る。終わり。
追記
http://b.hatena.ne.jp/amatanoyo/20100406#bookmark-20536320
自分で調べろクソが。ツールバーのウェブ履歴機能を指しているならPageRank調べるクエリで送られたURLを残しているので、httpsはホスト名まで、httpはクエリを除くURLになる。検索結果からクリックした場合はクエリ付きのhttpsのURLもウェブ履歴に残る。
翻訳機能をhttpsのページに対して使うと警告が出る http://gyazo.com/6df6b44f1f825e7e58896348f52793ea.png
ウェブページ翻訳はそもそもhttpsのページを翻訳できない http://gyazo.com/74331ff3bf3477e6c446e2b7f2137080.png
サイドウィキはhttpsのページに対しては使用できない http://www.google.com/support/toolbar/bin/answer.py?hl=jp&answer=157471
↧
法と技術とクローラと私
こんにちは、趣味や業務で大手ポータルサイトのサービスで稼働しているいくつかのクローラの開発とメンテナンスを行っているmalaです。
さて先日、岡崎市立中央図書館Webサイトをクロールしていた人が逮捕、勾留、実名報道されるという事件がありました。
関連URL: http://librahack.jp/
電話してみた的な話
- http://www.nantoka.com/~kei/diary/?20100622S1
- http://blog.rocaz.net/2010/06/945.html
- http://blog.rocaz.net/2010/07/951.html
この件につきまして法的なことはともかくとして技術者視点での私見を書きたいと思います。法的なことは差し置いて書きますが、それは法的なことを軽んじているわけではなく、法律の制定やら運用やらは、その法律によって影響が出る全ての人々の常識やら慣例やらも含めた実態に即していなければ意味が無いばかりか害悪になると考えるからです。また技術的に解決できる問題については、先ずは技術的な解決を試みるべきであって、特にインターネットの世界では、人間や機械がアクセス先のサービスの利用規約や、アクセス先のサーバーが置いてある国の法律を解釈することが必ずしも期待できないため、性善説もクソもない、機械が読めない法律や利用規約など、そもそも全く配慮されることを期待すべきではない!と考えるべきであり、また人間や機械がそのサービスに固有の利用規約やその国に固有の法律などを理解していたとしても、必ずしもそのルールが尊守されるとは限らないし、ルールが守られることを前提としたシステムの設計は技術的な欠陥が放置されることにつながり、結果として人々の安全やプライバシーを脅かす危険な存在であると言える。つまり、技術者の世界においては、地域や民族に固有のローカルルールや常識や慣例や風習に従わずに、技術的に解決すべきことは技術的に解決すべきであるというのが常識や慣例であり、そういったポリシーを法律家も含めて理解していただく必要があると考えています。
話を戻して、もし意見を聞かせてくれと言われたならば
- クローラには問題ない(刑事責任も民事責任もない)
- サービスの運用に支障をきたしているのであればアクセス拒否して終わり
- 処理能力の向上やバグの修正などの改善を求めるのは図書館と開発ベンダーで相談して勝手にやればいい
- 警察の対応が特別におかしい
と答えるでしょう。
もし自分が同様のクローラを書いたらどうなるか
個人的な感覚では、librahackさんが書いたクローラは当然悪意があるものだとは思わないし「特別に行儀が悪い」とも思わない。自分が同じ目的のプログラムを書いたならば、おそらく大差ない内容になるでしょう。
具体的には
- robots.txtを無視します
- metaタグを無視します
- ウェイトを入れません(入れるとしてもごく短い)
- 一部500エラーが出てもクロールの中止やプログラムの見直し等は行わない
- むしろ適切なウェイトと最大試行回数を設定した上でリトライすることを検討する
- 一度取得したページについてはキャッシュしてしばらくアクセスしないような制限を加えるが、開発中ならその限りではない
- 開発中、あるいは自分専用サービスとして作っている限りは、UserAgentを変えない(使用しているライブラリのデフォルト)
もちろん事前にアクセス先のサービスに対して何らかの知識があるなら、多少加味するだろうが、同様の事例であれば逮捕される可能性が高い。俺じゃなくてよかった。
なぜrobots.txtやmetaタグを無視しても良いと考えるのか
robots.txtやmetaタグによるbotの拒否は、ロボット型の検索エンジンのクローラが際限なく動的に生成されるリンクを辿っていって双方のサーバーリソースに過大な負荷をかけたり、公開されるべきでないコンテンツが検索エンジン経由で公開されたりといった事故を防ぐのが目的(という認識)なので、特定サービス向けに特定パターン以外のリンク先を探索しない個人的な使用目的の巡回ツールに対してまで、robots.txtやmetaタグの規定するルールを適用するのは適切ではないと考えているからです。
なぜウェイトを入れる必要がないと考えるのか
リクエストを並列して投げない(前回のリクエストの完了を待ってから次のリクエストを発行するようになっている)ならば、相手先のサーバーに対して与える負荷は限定的であり、一般ユーザーが通常の利用目的でブラウザを使ってかける負荷の上限と大差がないと考えるからです。更新チェックなどの目的で同一の(更新されている確率が低い)URLに対してウェイトを入れずに数秒、数分の間隔で自動アクセスするのは、非常識であると考えます。しかし、同じURLに対する重複したアクセスがなく、同一ドメインのリンク先をn段階辿ってまとめて保存するような機能は、本来ブラウザに備わっていてもおかしくないようなもので、自前で書いたツールを使っているだけで通常のブラウジング行為の延長線上であると捉えるべきです。古いIEには実際そういう機能がありました(ウェイト入れてたかどうかとかは調べてない)。
なぜ500エラーが出てもクロールを中止する必要がないと考えるのか
自分のリクエストが原因でエラーが出ているのか区別がつかないので、単に時間をおいて再試行すれば良いと考えるからです。全てのレスポンスがエラーを返すようになったならば、その段階で目的が達成できないのでプログラムの見直しを行うことになるでしょう。500レスポンスは単にそのリクエストに対してエラーが出ているというだけなので、自分のリクエストに原因があるとは考えません。なのでこの場合の適切なエラーハンドリングはクロールの停止やプログラム開発の停止ではありません(適切なウェイトを入れた上で再試行します)。もし403エラーが返ってきているのであれば、自分のリクエストが何らかの理由で拒否されているだろうから、処理内容を見直す必要があると考えます。403レスポンスが返ってきたら、別のUAや別の回線からのアクセスを試して、何らかの自動的な制限に引っかかったのか、あるいは自分の書いたプログラムが決め打ちでアクセス拒否されているかどうかを判断したうえで、サービス運営者に問い合わせるなどするでしょう(アクセス拒否されないためにはどうすればいいか聞く)。気軽に問い合わせできる感じでなかったら開発を中止する。
botがサービス運営に支障を来す場合にサービス運営者の取るべき行動について
- 使用しているhttpdのマニュアルとにらめっこして該当のbotに対して403を返すようにしましょう
- もし過剰なアクセスにより金銭的な負担が発生しているのであれば402 payment requiredを返すのも良いでしょう。youtubeが使っています。
- 手動でルールを追加するのが面倒であればIPアドレス毎の帯域制限やアクセス回数の制限を行ないましょう。大抵のhttpdで適切なモジュールがあるはずです。
- 403を返すだけの処理だけでもサーバーのリソースを大量に消費してサービス運営に支障が出るレベルのアクセス回数であるのなら、iptablesで拒否するなどしましょう。
- アクセス拒否されていることを検知して自動的に複数のIPアドレスからのアクセスを行って来たり、UserAgentを偽装してアクセス拒否することを困難にしていたり、帯域の消費だけでサービス運営に支障をきたすようなレベルであれば攻撃とみなしましょう。警察の出番だ。
行儀の良いbotの話
- ウェイトを入れるのは良い慣習だ。
- エラーが返ってきたらクロール頻度を調整するのは良い慣習だ。
- botの目的や連絡先が分かるようにするのは良い慣習だ。
botの世界には実効性があるのかどうか不明な慣習があります。これらを守ってなくても大した問題ではないと考えています。
- Fromヘッダにメールアドレスを入れる → アクセスログに残らない、自称しているだけで確実にそのメールアドレスの持ち主とは限らない
- 過負荷時のRetry-Afterヘッダ → 守ってくれなければ意味が無い、行儀の悪いbotはそもそも守らない、処理能力改善することを考えたほうがマシ
これらはあくまで良い慣習であって、守っていないからと言って悪意があるものだとは言えない。ライブラリの機能を叩いて3分で作れるような書き捨てのスクリプトでいちいちそのようなことが配慮されることを期待すべきではない。攻撃目的で作られたツールというものは、もっと行儀が悪いものであることを知るべきだ。
攻撃目的で作られたツールではなくても問題になることはある。困ったことになる代表例は
- ab(Apache Bench)を管理外のサーバーに対して行う → 普通に落ちたり帯域使い尽くしたりする
- 脆弱性スキャンツールの類 → 脆弱性ある無しに関係なく大量のリクエストを投げるし場合によっては何かデータ書き込んだりする
これでサービスを落とした人の実例を何件か知っている。
まとめ
403返して終わりって事例でポリス沙汰にするな。
↧
↧
図書館クロール補足
なんか技術的におかしなことを言っている人がいたら追記していくかも知れません。
クロール頻度が妥当かどうかの話
ウェブサーバーはマルチスレッド、マルチプロセスなどで複数のリクエストを同時に処理できるようになっているのが一般的であるため「前回のリクエストが完了してから、次のリクエストを投げる」実装になっている限りは「サーバーの性能を100%使いきって他の利用者が利用できない状態」になることは、通常起きません。
例外的なケースもあります。
- ウェブサーバーがリクエスト完了後に何らかの処理を行うような実装になっていて、リクエストのペースによっては処理が溜まっていって追いつかなくなる。
- ロードバランサ、リバースプロキシを使ったフロントエンド/バックエンドの構成になっているサーバーで、フロントエンドがタイムアウトと判断して早々にエラーを返したが実際はバックエンドで処理が続いている。
例えば1秒で処理が終わらないページ(例:LIKE検索)に対して、レスポンスの受信を待たずに1秒に1回のペースでリクエストを投げ続けたら、サービス停止を引き起こせるでしょう。ですが、並列してリクエストを投げていないのに「お前のリクエストが原因で他の利用者が利用できない状態になった」という主旨のことを言われたのであれば、それは通常言いがかりです。他の利用者のリクエストと合わせて過負荷状態になっている(一人の責任にされるべきものではない)か、アプリケーションのバグが原因の事故であると考えるのが自然です。
「サーバーリソースが限られているので遠慮してくれ」というのは、別段おかしなことではありません。が、サービス停止の責任を追求されるのは異常なことです。
1秒1回のペースが妥当かどうかとか、どの程度のウェイトを入れるべきなのかという話は、クロール対象のサービスの規模や、静的ページか動的ページかなどによっても変わるでしょう。もし書いたプログラムを配布する場合は、複数の利用者によってリクエストが同時に投げられることになるので、慎重さが要求されるでしょう。
開発中で自分の手元でしか動いていない相手先のサーバーに並列アクセスしないクローラが原因でサービスが落ちて他の利用者が迷惑しているといって責任を追求されるというのは、技術的におかしいことを言われているのです。それは予見できない事故です。並列アクセスしてないのにサーバーが落ちるのであれば、それはサーバー側のバグが原因である可能性が高い(実際そういう考察をしている人が何人かいますね)。
という程度のことを警察が判断できるようになると良いですね。
適切なエラーハンドリングについて
http://librahack.jp/okazaki-library-case/conclusion.html
相手サーバからのレスポンスHTTP500を細かくハンドリングせず単にスキップだけしていた
これ特におかしなことではないです。おかしいと思っている人は、今回のケースでエラー処理を怠ることによって相手先のサーバーに何か損害を与えうると考えていますか?むしろ不適切なエラー処理(際限なくリトライなど)をしたほうが損害を与える可能性が高いです。
一部の特に行儀の良いクローラであれば500エラーが返ってきた際に同一のサーバーに対するクロール頻度を下げるなどするでしょう。一度エラーが起きたURLに対してリクエスト内容を修正せずに、間を置かずにリクエストを繰り返すのは、同様のエラーが返ってくる可能性が高いので避けるべきです。しかしスキップして次のURLを取得するのであれば、別のリクエストですから正常に返ってくる可能性があります。
連続して500エラーを返していた場合でも、それが自分のリクエストによってサービスダウンを招いているという(並列アクセスを捌けるサーバーに並列アクセスしてないのに自分のリクエストだけが原因でサービスダウンが引き起こされることは無いだろうという技術者としての常識を覆しての)推測は通常されるものではありません。ましてや500エラーから図書館業務が妨害されたことを推測してクロールを中止せよというのは無茶苦茶なことを求めています。
ちなみに503エラーであればサーバーが過負荷かメンテナンスです。時間をおかずに次のURLにアクセスしても503の可能性が高いです。サーバーの負荷が高いためウェイトを入れてくれというのは、Retry-AfterというマイナーなHTTPヘッダを使うことで実現できます。ただしRetry-Afterを出力するサービスも考慮するクローラも、ぶっちゃけあまり無いと思います。Google Code Searchで検索したところいくつか実装例が出てきましたが、数少ないです。
http://www.studyinghttp.net/status_code#Code503
逆に問題があるエラーハンドリングは以下のようなものでしょう(サーバーが落ちても良いと思っていると判断されかねないもの)
- エラーが解消されるまで(適切なウェイトや最大試行回数を考慮せずに)リトライする
- 負荷が原因でアクセス制限を受けているということを知った上で、アクセス制限を回避するための工夫をする。
正しい技術的知見の適切な啓蒙について
ソフトウェアのバグ、脆弱性、不具合であれば、それが直ったかどうかが明確に判別が出来るだろうし、時にはそのようなバグは恥ずかしいと非難を浴びせることもあるでしょう(それが技術レベルの向上に繋がることもあります)。しかし「クローラにどの程度の安全機構を組み込むのか」という問題になると、人によって感覚が異なるようです。事故を起こさないためにどの程度の対策をしておけばいいのかというのは、個々の経験則に依る部分が大きいのでしょう。(ここで交通事故に例えるのは不適切です)
私が主張したいのは以下のようなことです(クローラに限った話ではなく一般論として)
- お前らは人が趣味で数時間で作った程度のものに一体どの程度のレベルを要求しているのか、身の程を知れ。
- 実態を知らない初心者(もしくは老害)が「これぐらいのことやって当然だよね」などと平然と口にする、何様のつもりだ。
- 普段はまるで問題にしていないようなことを事故が起きたときに限って「過失があった」といって騒ぎ立てるなクズども。
世の中で稼働しているソフトウェアはバグだらけです、例えばオープンソースプロダクトのChangesを読めばわかるでしょう。仕様やプロトコルを守っているソフトウェアばかりではないし、それでも世の中は動くように出来ているのです。全くお前らは人のミスを責めたてることにばかり夢中で全く生産的ではないばかりか、時に全く問題のないことに対してまで、過失があった、不注意であったと、騒ぎ立てて間違いを広める。そのような行為は啓蒙ではないし、害悪だ。
良いクローラの条件
自分が考える良いクローラの条件は、事故起こさない方法を追求しても限度があるので「何か問題が起きた場合にアクセス拒否する方法が分かりやすい」ことです。アクセス拒否したときに他のユーザーが巻き添えを食わないことなども含みます(動的IPやブラウザに偽装してたりすると面倒)。今回の事件に関して言えば、最初に稼働させたのが固定IPのレンタルサーバーなので、まあ問題ないでしょう。そもそも図書館側がアクセス拒否する方法を知らなかった可能性がある。
という程度のことを警察が判断できるようになると良いですね。
↧
最近のネットデマについて
- ソースをろくに確認せずに取り敢えず拡散する
- 自分の発言の責任が希薄になるように計算されたテンプレート
- 詳細はリンク先で
- 真偽不明ですが取り敢えず拡散
- 自己責任で
- 元情報が訂正されても、拡散した誤情報は消えない
「あなたのGmailをすべて盗まれる」問題
- http://b.hatena.ne.jp/entry/jp.techcrunch.com/archives/20101120whoa-google-thats-a-pretty-big-security-hole/
- http://topsy.com/jp.techcrunch.com/archives/20101120whoa-google-thats-a-pretty-big-security-hole/
- http://disqus.com/guest/84d6bff45c2112e083c425e39f954f5e/
- http://twitter.com/yomoyomo/status/6692549821464576
「メールアドレス」を「メール」と誤解したのはともかく「すべて」はどっから出てきたんだ「すべて」は。面白おかしく大げさにかきたてようとしてるからこういうことになるんじゃないのか?この情報を拡散したバカどもは「(編集部からの修正とお詫び)記事の見出しに「Gmailをすべて盗まれる」とありますが、正しくはGoogleにログインしている(Gmailの)メールアドレスを盗まれるが正しい表現でした。修正してお詫びいたします。(2010年11月27日)」という文言を読みましたか?
mixiアプリで個人情報漏洩する騒動
- 12/06日現在 twitterでの言及 約6500件 http://topsy.com/mixi.jp/manage_acl.pl
- 12/06日現在 mixi内 1276件 http://mixi.jp/search_diary.pl?keyword=http%3A%2F%2Fmixi.jp%2Fmanage_acl.pl&x=0&y=0&submit=search&type=dia
メールアドレスからmixiアカウントを検索できる機能が問題になったのは記憶に新しいが、
- メールアドレスを知っているが、その持ち主を知らない
- メールアドレスと、その持ち主を知っているが、mixiアカウントを知らない
というケース、つまり文字列は知っているが関係性を知らない、というケースで「非公開の情報」がデフォルトで公開になった。だから問題が起きた。
それに対してこれ http://mixi.jp/manage_acl.plは 元々「(mixi内で全体)公開されている情報」をAPI経由で取得できるようにするか、という設定だ。そのユーザーのマイミク一覧も、マイミク一覧から辿って取得できる全体公開されているプロフィールも、mixiアカウントを持っていれば誰でもアクセスできる情報だ。(実際に大量に取得しようとしたら足あと付けまくってアクセス制限を受けるだろうが)
他のサービスと比較してみよう
- twitterはprotected(許可した人にのみ公開)にしていても(あなたのフォロワーが許可すれば)OAuthで第三者から読まれるし、それを拒否することは出来ない。
- twitterのDM(特定相手にのみ届くメッセージ)であっても(送信先の相手が許可すれば)OAuthで第三者から読まれるし、それを拒否することは出来ない。
- あなたが送ったメールを第三者に見られたくないと思っていてもGmailは(あなたの友人が許可すれば)OAuthでアクセスすることが出来る http://code.google.com/intl/ja/apis/gmail/oauth/
- あなたがメールアドレスを第三者に知られたくないと思っていても(あなたの友人が許可すれば)Google Contacts APIを通じて取得することが出来る http://code.google.com/intl/ja/apis/contacts/
mixiは「あなたの友人が許可しても」全体公開ではない情報にはアクセス出来ない、という世界的に成功しているグローバルなサービスと比較して見ると極めて消極的で限定的なアクセスしか許可していない(参考: http://developer.mixi.co.jp/appli/spec/pc/permission_model )
このデフォルト設定を本気で不適切だと思っている人は、今すぐTwitterとかGoogleとか使うのやめた方がいいし、gmail使ってる人にメール送るのも止めた方がいいし、アドレス帳に入らないように関わるのも避けたほうがいい。Twitter上で言及している人間は滑稽だ。
その設定は危険だから今すぐ変えましょう、などと言われてホイホイ変える人間は逆の行動も容易に起こすので、例えば
- 安全のためと言われて偽セキュリティソフトをインストールしたり
- パスワードの変更したほうが良いと促されて偽サイトにパスワードを入力したり
- PCを高速化するコマンドだと言われてHDDをフォーマットするコマンドを入力したり
- 体に良いと言って水銀をゴクゴク飲んだり、お節介で井戸水に水銀を入れたりする
つまり人間が大量に死ぬ、暴動が起こり核戦争で人類が滅びる。
ネットデマを防ぐために今、我々が出来ること
そのような人間を忘年会に誘うのを止めろ!
↧
プログラマが知るべき97のことに寄稿していません
12月18日にオライリーから発売されるプログラマが知るべき97のことに寄稿していません。

- 作者:和田卓人,Kevlin Henney,夏目大
- 出版社/メーカー:オライリージャパン
- 発売日: 2010/12/18
- メディア:単行本(ソフトカバー)
- 購入: 58人 クリック: 2,107回
- この商品を含むブログ (350件) を見る
↧
任天堂スペインから個人情報盗んでハッカーが脅迫したとされる事件について
スペインの話なんだけど
http://www.inside-games.jp/article/2011/02/15/47390.html
「脅迫事件」であるのに、犯人が何を要求していたのか分からないというニュース記事で、大変な違和感がある。そして参考リンクのAFP通信の記事を読んでも良くわからない。軽く調べた結果、任天堂スペインのなんかのキャンペーンのサイトにとてもひどい脆弱性があり個人情報を取得したハッカー(adan_geckoさん)が脆弱性の報告と共にお前のサイトは個人情報保護のための適切な手段をとっておらず犯罪なのでデータ保護当局に告発する用意がある、法的トラブルを避けるために交渉したいと電話番号書いたメールを送信、サイトは停止、adan_geckoさんがelotrolaob.netのフォーラム上で脆弱性があったこと個人情報を入手していることを告白、脅迫と受け取られてスペインのメディアが2つほど報道、adan_geckoさん任天堂に対するメールの内容と脆弱性の詳細をフォーラム上で公開、数日後逮捕、警察が発表「4000人の個人情報が一般公開されるのを防いだ」、英語圏メディア報道、という経緯のようだ。
スペイン語で事件の経緯がまとまっている。Google翻訳http://translate.google.com/など使って読める。
- イベント詳細 http://www.elotrolado.net/wiki/Prueba_y_ver%C3%A1s
- 事件の詳細 http://www.elotrolado.net/wiki/Caso_Prueba_y_ver%C3%A1s
- 議論してるスレッド http://www.elotrolado.net/hilo_hilo-oficial-caso-quot-prueba-y-veras-quot_1571331
機械翻訳だが引用する
データにアクセスするための手順: (明らかに我々ができなくなります場合は、それは私の一部には非常に無責任な可能性もあるそうだが) アクセスが http://admin.pruebayveras.com 。 を押して、ユーザー名とパスワードを入力せずに入力してください。 ほら! あなたは、彼らが"技術をハッキング"されていることと思いますか?
ずさんなセキュリティを棚にあげて被害者であることを強調するのはまさにサイバーノーガード戦法に通じるところがあり、これはひょっとすると、admin画面に認証がかかっていなかったため、不正アクセスやハッキングの罪を(向こうではどういう基準なのか分からないが)適用することができないので、脅迫として無理やり逮捕したのではないだろうか。機械翻訳なので正確なニュアンスが分からないのだが、フォーラム上でも指摘されてるのでメールの内容は実際に「脅迫」だと受け取られる可能性はあるのだろう。しかし脆弱性を発見してそれにともなって個人情報を入手してしまっている場合に、どうするのが適切な対応なのだろうか、認証がかかっていない管理画面とはいえ不正アクセスだ何だのと茶番のような裁判を繰り広げることになる可能性は充分にある。もし俺が同じ立場であったならば「要求」するのはこういったことだろう。「入手した個人情報の消去の引換に、法的手段に訴えないことを保証してくれ」
もしハッキングを受けたとして法的手段を取られた場合に、容疑者は裁判に巻き込まれて面倒なことになり、任天堂はずさんなセキュリティだったことが公にされて評判が下がり、両者ともに損をすることになる。ハッカー側には「個人情報の消去」や「脆弱性の詳細を公表しない」、任天堂側には「法的手段に出ない」「サイトの停止についてユーザーに誠意のある告知をする」「謝礼」などの交渉材料があっただろう。(スペインにおけるPマーク的なものがどうなっているのか知らないが、事故が起こったことを当局に報告する義務があるのかもしれないがそれはさておき)
犯人が愉快犯であることも可能性に入れた上で、個人情報が公開されないことを最優先として考えた場合に、警察沙汰にすることは正しい選択であるかもしれない。しかしながら(機械翻訳なので正しいニュアンスが伝わっていないかもしれないが)個人的にはadan_geckoさんの振る舞いは、充分に紳士的に思える。なぜならば、悪意のある人間であれば、修正前に公表されるし、とっくにすべての個人情報が漏洩しているし、犯人を特定することができないか、あるいは逮捕しても無駄な状況になっているだろうからだ。身元を明らかにした上で対話の用意があると連絡してきた時点で、充分に紳士的な振る舞いだ。もしスペイン語に堪能な人がいたら犯人のメールが脅迫と読めるのかどうか「4000人分の個人情報をオンライン上で公開する用意がある」なのか「データ保護当局に告発する用意がある」なのか、次々に個人情報を公開していってやがてすべての情報を公開するつもりがあったのかどうか、正確な翻訳を教えてほしい。少なくとも機械翻訳では4000人分の個人情報をオンライン上に公開する意思があると書かれているようには全く読めなかった。非公開のメールでそういうやりとりがあった可能性も否定できないし、あるいは本当はものすごい高度なハッキング技術で個人情報を取得したのにパスワードが必要ない状態だったと吹聴して印象操作している可能性も無くはないだろうが、いくつかのメディアの報道は警察発表を鵜呑みにして、中立性を欠いており、事実を正確に伝えようとしていない、と思える。事実を正確に把握した上で「交渉が下手だ」とか「そのような行いは正しくない」だとか、そういう批判もあるだろう。しかしろくに取材をしないで警察発表や企業の言い分を鵜呑みにして印象操作の道具にされてしまうようなメディアは本当に世界的に残念なインターネットだ。
報道した英語のメディア
↧
↧
主人がFacebookアカウントを剥奪されて3週間が過ぎました
http://ma.la/fb/というのを書いたので、経緯と補足を書きます。
読むのが面倒くさい人向けに、ものすごく簡単に要約しておきます。
- Facebookにはリンクを他人と共有するいいねボタン(likeボタン)というのがある。
- Facebookの「ファンページ」なるものをつくると、いいねボタンを押したのが誰だか分かる機能がある。
- ユーザーに気付かれないように細工したiframe内のボタンをクリックさせたりするクリックジャッキングという攻撃手法があり、いいねボタンを強制的に押させることが出来る
- これによって悪意のあるサイトは、訪問者のFacebookアカウントを特定することが出来る
- Facebookの場合は実名登録の利用規約を強く徹底しているので、本名を登録してるならば(例えば日本の法律においては個人情報と定義されているところの)本名が分かる
クリックジャッキングは方法の一つでしか無くて、主旨ではありません。これはFacebookの設計上の問題の一面にしか触れておらず、あとでサードパーティCookieについての問題を書く予定です。
アカウント停止後の経緯とかやり取りとか
今までの経緯をさらりと書く。
- 3/2 Facebookアカウントが停止される、自動確認のメール送る、返事を出す
- 3/3 facebook -> me Facebookから最初の返事、テンプレっぽい。身分証を送れというもの
- 3/3 me ->facebook免許持ってないよ。この写真じゃ駄目か、と年賀状の写真送る。
- アカウントは個人利用、ハンドルネームじゃなくて実世界で使ってる名前だと強調。
- いくつかma.laで実世界での活動実績が分かるリンク貼る
- 3/8 facebook -> me 大体5日程度で返事が来るようだ。
- 不便をかけて謝るが政府発行の写真付き証明書じゃないと駄目
- そうじゃないとあなたのリクエストを処理できない
- 3/9 me ->facebookこのようなメールを送る https://gist.github.com/859854
- 要約すると、お前のサイトのセキュリティがダメダメだから今の状態で個人情報を入れたくないよ、セキュリティ担当者と代われ
- 3/15 facebook -> me 返事が来る。長いが主に利用規約のコピペ。言ってることは同じ。
- セキュリティ担当者に転送しろと言ったのにスルーされる。
ここまでが前回のあらすじで、Cookpadごはん日記までチェックしている俺の熱心なストーカーの皆さんは御存知のとおりです。
- 3/16 このままでは進展しないので、もっとマシな方法で連絡を取ろうと試みる。
- 3/17 2つほど@を飛ばすが返事なし。
- 3/17 Facebookの問題点について英語で書くの大変なので取り敢えず日本語で書く。後で誰かに翻訳してもらおう。
- 3/18 Facebook日本法人代表から相変わらず返事なし。その間、東京電力公式アカウントをフォローしたのを確認したのでtwitterを見ているがreplyを無視してるのだろうと推測する。
- 3/18 Facebook日本法人代表がフォローしている誰かを経由してtwitterのDMを送ってらうことを画策する。
- 3/18 mixiのCTOに送る。mixiにも関係する内容なので。すぐに転送してもらう。
- 3/19 児玉太郎氏連絡が取れてtwitterのDMが来る。メールを送る。
- 停止されたアカウントについて
- セキュリティ上の問題点については、必要だったら認証かけるよ
- 3/19 児玉太郎氏からメールの返信が来る。
- セキュリティについて:問題を認識しており調査中 アカウントについて:特別対応可能か調整してみるとのこと。
- 3/22 本社のユーザーオペレーションから日本語のメール。
- 「お客様の実名をお知らせいただき次第、こちらでお客様のお名前を変更し、アカウントを再開いたします。」
- プライバシー設定についてのコピペが付いてくる。
- 実名を知らせたくない場合はファンページを作れるとか、検索エンジン向けの公開設定が出来るとか。
- 3/22 すぐにMa Laが本名ですと送る
- 今まで送ったメールの内容をまるで無視して日本語で書きなおしただけに思われたので、再度情報共有するようにと書く。
- こちらが指摘したセキュリティ上の問題点に対しての解決策になってない。
- 自分はユーザーとして「私のプライバシーが心配、不安」ということではなく技術者として「脆弱性がある」と主張している。
- 3/25 すぐに対応するみたいに書いてあるのに返事が来ない。
- 3/25 http://ma.la/fb/を twitterに張る。
- 3/26 だいたい8時間後にFacebookから返事が来る。
まだやりとり中なので仔細は省くけど、大まかな流れはこんなところ。この手の問題に対するサービス側、ユーザー側で取れる対策方法とサードパーティCookieの問題についても別途書かないといけない。さて日本法人代表とコンタクトを取ることによって、本名だと主張して利用規約のコピペが返ってくるという、アカウントの復帰もできないし脆弱性についての議論もできないというループ状況から一歩前進したわけであった。
児玉太郎氏への私信、公開質問状
今さっき、Facebook日本法人代表の児玉太郎氏から「対策が完了している」という主旨のメールがあった。
そして案内されたURLがこちらだ http://forum.developers.facebook.net/viewtopic.php?pid=327314
私が指摘した問題は解決していません。また、対策完了の連絡を受ける前にFacebook本社ユーザーオペレーションの人から「クリックジャッキングが行われていると疑われるページ」を検知する改良を行っているという連絡を受けています。そして、そういった対策方法の問題点は既にこちらから送ったメールに書いた通りで、問題について正しく認識していないようなので大変残念に思っています。
問題について正確に理解していないようなので補足します。
- ユーザーにリンクを強制的に投稿させることで、宣伝リンクを拡散させるspam行為や、ブラウザやプラグインの脆弱性を利用したマルウェアの配布に使われるといった問題があります。
- そしてこういった問題は、過去にも指摘されていますし、幾つかのニュースサイトが取り上げたのも記憶にあります。
- 3/17に書いた文章内に書いてあるとおりですが、クリックジャッキング対策のコードがFacebook内に含まれているのを認識しています、その上で書いています。
自分が指摘しているのは、linkが他者と共有されることによってspam行為やマルウェアの配布に使われる、という点ではなく「誰がボタンを押したのかが分かる」ということです。今のところ私が認識しているのはファンページの管理者が、誰がいいねボタンを押したのかを把握することができます。そして、クリックジャッキングによって強制的にボタンを押すことが出来る、あるいは、iframeのデザインによって「自分が何についていいねボタンを押そうとしているのかを認識できない状態」でボタンを押すことが出来るのが問題だと主張しています。これによってユーザーは自分のFacebookアカウントが第三者に通知されることを認識しないままでlikeボタンをクリックします。
そこのところを取り違えないようにしてもらいたいと思います。また「全力で取り組む」「真剣に考えている」といった精神論ではなく、具体的な対策や問題が解決したか(する予定があるか)どうかを確認したいと思っています。
継続中なので
何か進展があったらまた書きます。
↧
mixi足あと廃止に寄せて
mixiが6年以上に渡って放置してきた足あと機能を使って訪問者の個人特定が可能な脆弱性を修正した。簡単に説明するとmixi以外のサイトからでもユーザーに気付かれずに、その人のmixiアカウントを特定するということが出来たが、出来なくなった。(正確にはユーザーが気付いたとしても特定された後)
アダルトサイトが訪問者のmixiアカウント収集したり、ワンクリック詐欺サイトがmixiアカウント特定して追い込みかけたり、知らない人からメッセージ送られてきてURL開いたらmixiアカウント特定されてたり、そういうことが今まで出来ていたのが出来なくなった。
過去にもいろんな人が言及してるし、すでに終わった議論だと思ってる人もいるだろう。世間一般にどれぐらい認知されていたのかはよく分からないが、少なくとも技術者やセキュリティ研究者の間ではよく知られている問題だった。
- http://internet.kill.jp/wiki/index.php?%B5%BB%BD%D1%2Fmixi%C2%AD%A4%A2%A4%C8%A5%ED%A5%B0%CC%E4%C2%EA%A4%DE%A4%C8%A4%E1%A5%B5%A5%A4%A5%C8
- http://www.fladdict.net/blog-jp/archives/2005/12/mixi.php
- http://d.hatena.ne.jp/yaneurao/20060202#p1
- http://hxxk.jp/2006/02/03/0007
- http://twitter.com/#!/lumin/status/77772103918690305
twitterに書いて結構RTとかされたんだけど、多分周知が十分ではない気がする
「訪問履歴が残る」という部分については今でも検証できるので、キャプチャを取っておいた
自分はこの修正を全面的にではないが支持している。が、足あと機能の復活を求める署名運動などが始まって色々面白いことになってて、あー、この人達は足あと機能の存在に何の疑問も持ってこなかったのかー平和だなーと思っていたのだけど、色々見過ごせないことが多くなってきたのでブログに書く次第です。
何のためにこんなことを書いているのか
足あと機能の廃止によってセキュリティが低下したとする主張を見過ごすことが出来ないためです。
典型的にはこういったものです
すべての足あとが表示されないのはセキュリティ上不安
新しい『先週の訪問者』では、「友人」「友人の友人」「mixi同級生」「同僚ネットワーク」 しか表示されない。
つまり、全く関係ない垢の他人や第三者は一切表示されなくなります。
これでは、何らかの悪意を持つ誰かが「ログイン時間のチェック」を繰り返すなどのストーカー行為を繰り返していても対処ができくなる。
また、誰が日記を読みにきたかもわからない。
・反対派の会員の間には、リアルタイムでの足あと表示がなくなることにより
「ストーカー対策やプライバシー保護などに関して、 セキュリティの低下では
ないか?」と心配する意見も出ているようですが、御社としてはどのようにお考
えでしょうか?
自分の情報を誰が参照したのか分かるようにする、という方式のセキュリティも勿論あるだろうし、それについて否定をしているわけではない。しかし、足あと機能が存在することによって生じてきたセキュリティやプライバシー上の問題について十分な理解のないままで「セキュリティが低下した」という主張を通すのは無理がある。ストーカー行為を問題だとするならば、ストーカーが足あと機能を使ってあなたのmixiアカウントを特定するといったことも出来た。そのユーザーに関する全てのページで足あとが付くわけでも無かったし、例えばマイミク一覧を表示するlist_friend.plなんかは足あとが付かないしマイミクの増減監視して交際関係にあった誰と誰が別れただとか特定するネットストーカーの話なんてのは、皆さんよくご存知のとおりですね。足あと機能を監視カメラに例えている人がいたが、その監視カメラはそもそも写らないこともあってぶっ壊れていたし、取り外してmixiの外に設置することが出来た。
アカウント特定されて何か問題あるの?
外部サイトからアカウントを特定される問題について述べたときに「どうせ漏れるのは公開情報なので問題が無い」という主張をする人が(たまに)居るのだけど、それは問題を軽視している。もちろん秘密の情報を読み取られる方が、深刻な脆弱性ということになるけれど、あなたが匿名でいることを選択したときに(自分が誰であるのかをまだ教えていないときに)相手にとって自分が誰であるのかということは「非公開情報」だ。
ログインしたままで居ると他のサイトからでも情報を取得できる(他のサイトに入力した情報が読み取られる)ということが、脆弱性ではなく「そういうものだ」と受け入れられてしまってはいけない。それは、インターネットにおけるサービス全般の信用を損ねてしまうからだ。(ただし、現実的な問題として、この手の脆弱性は多くのサイトにあるので、ユーザーが適宜ブラウザのシークレットモードを使うなどして自衛したほうがいい)
外部サイトで把握している既存のidと関連付けられたり、収集したidが売り渡されたり、交換されたりする行為が行われていてもユーザーが気付くことが出来ず、技術的・法的に十分な抑止力がない。ついでに、mixiがソーシャルアプリのサードパーティに対して生のユーザーidを渡さないようにするという変更方針を出してることも参考にすべきで、足あと機能を通じて訪問者のidを気軽に取得できるという状況を放置したままで、こういった変更を行っても片手落ちということになる(優先順序おかしいとツッコミが入るだろう) http://developer.mixi.co.jp/news/news_apps/16239/
mixiは足あとを使ったトラッキングについて知っていたのか?
勿論知ってる。6年前から知ってる。笠原社長も知っている。知っていたが対策をしてこなかった。
- http://b.hatena.ne.jp/kusigahama/20060203#bookmark-1329065
- http://yagi.xrea.jp/2005/12/mixilogfull.png
また、方法は違うけれどFacebookにおいても同様の問題、訪問者のアカウントを意図せずに取得可能である(実名登録してれば実名がわかる)という文章を書いてFacebook日本法人の社長に送りつける際にmixiのCTOを伝言係に使った(前回の日記参照)。その際に「mixiにも関係のあることだと思います」と言付けしたので、そういった行動がmixiの判断に何らかの影響を与えた可能性がありますが17000人に恨まれるのはゴメンだ。
悪用されないように対策すればいいだけじゃないの?
外部サイトに埋め込まれた場合には足あとを付けないという対策は出来ます。簡単にいえばmixiのページを表示した後に、追加で足あとを記録するための画像をロードするなりスクリプトを実行するようにすれば可能です。そういった変更を加えることで意図せずに足あとを付ける、というケースを防ぐことが出来ますが、その場合には(ブラウザ内で行われる足あと記録のための処理をブロックすることで)足あとを付けずに訪問することも可能になります。足あと機能を監視カメラの類だと思っている人からすれば、訪問しても足あとを残さない抜け穴を作ることになります。
「悪用されないように脆弱性だけ修正することはできないの?」か、と言われれば「大幅な仕様変更を加えない限り、不完全な対策しか出来ない」 http://twitter.com/#!/bulkneets/status/103836004267458560
なぜ5年も6年も放置されてた問題を今直す必要があるのか?
UIエンジニア的観点から言うと、イイネボタンが読んだことを伝える機能の代替手段として十分に機能するだろうという算段が整ったからでしょう。そして一部のユーザーの反発を買っているが、いつものことで仕方ないと思ってるんでしょう。提示された代案が今よりマシではないと認識されることで「難しいことは分からないけど、悪用する人がいなければいいだけでしょ、良いから元に戻して!!」という感情的な反対運動に押しつぶされてしまうことを危惧しています。大変ですね。
セキュリティリサーチャー的な観点から言うと「CSRF脆弱性を放置したままログイン状態で外部サイトを訪問することを前提とした機能を開発すること自体が誤り」かつ「ブラウザがサードパーティCookieの送信をデフォルトでブロックするような流れにもなってない」ので、今、修正しないといけない。ブラウザが外部リソースをロードする際に「個人を特定しないように無個性化・匿名化してリクエストする」というのが、もしも一般的になっていたとすれば、mixi側でこの問題を解決する必要はなかった。(あくまで外部サイト埋め込みの場合は。バレても良い前提でmixiのURLを踏ませる場合には対策にならない)
もう少しくだけた言い方で書くと「それはmixiの仕様なので使い終わったらログアウトしてください」という言い訳が、もはや通用しなくなった。mixi自身が外部のWebサイトに対する埋込みのイイネボタンなどを提供するようになり、mixiにログインしっぱなしでネットサーフィンしてくれないと外部サイトとの連携機能の魅力が無くなってしまうからだ。こういった状況で「mixiにログインしたまま外部サイトを訪問すると意図せずにmixiアカウントを特定されるリスクがありますよ」と周知させないでいるのは、ユーザーに対する不義理であるだろう。
それから単純に5年6年前と比べてmixiのユーザーが増えた(訪問者がmixiにログインしている確率が高くなった)ので悪用されるリスクが高くなったというのもあるだろう。
こんな記事書いてるお前はmixiと何らかの関わりがあるのか?
親しいエンジニアが何人かいます。memcachedのデバッグ手伝ったらレッドブルが一箱送られて来たり、関連サービスの脆弱性を指摘したら茶菓子とコーヒーが送られてきたことがあるし、守秘義務に反しない程度の範囲で内情とか裏側についての情報交換をすることもある。お世話になっております、ありがとうございます、しかし俺はmixiに脆弱性があったということを大々的に広めようとしているわけですから、蜂の巣をつつくな余計なことを言うなと思われているでしょう。どうせ炎上するならそっちの方がマシだ!!!この件については何も聞いてないし俺の独断で勝手にやってる。
mixiやコミュニティに望んでいること
足あと機能に存在していた問題点について理解した上で、もう一度足あと機能が必要なものかどうか考えなおして欲しい。少なくとも「他人の足あとがリアルタイム」で表示されるのは、プライバシー・セキュリティ上の問題が大きいものだということを理解した上で議論して欲しい。
に書いてあるけど、自分は「友人はリアルタイムに反映でもいいんじゃねーの」という考えで、セキュリティ上の問題がある形で復活するようなことが無ければどうでもいい。
蛇足だけれど、足あと機能の復活を望んで署名をしているのは本当に一般ユーザーだけなのだろうか?「赤の他人の足あとも表示して欲しい」という点に重きをおいた主張をするのは、もしかすると「足あとspam行為によるアクセス稼ぎ」や「強制足あとによるid収集や名寄せ行為」によって、利益を得ていた側の人達が紛れていて扇動をしているのではないか、という邪推をしてしまう(特定の人物がそうだと言っているわけではないが、署名の水増し程度なら簡単にできる)
長文乙、終わり。
↧
サードパーティCookieの歴史と現状 Part1 前提知識の共有
Web開発者のためのサードパーティCookieやらトラッキングやらの問題点について三回ぐらいに分けて書きます。
この文章は個人的に書いていますので、おい、お前のところのサービスがサードパーティCookieに依存してるじゃねーかというツッコミがあるかもしれないが、そういうことを気にしているといつまで経っても公開できないという問題が出てしまうので、そんなことはお構いなしに書く。ちなみに例外なく自社サービスに対してもサードパーティCookieに依存するな死ねと言っている。これはWebプログラマー観点で、自分がサービス開発に関わる上で知っておかねばならないだろう知識として十数年間だらだらとWebを見ていて自然に知っていたものと、あるいは興味を持って率先して調べたものが含まれている。ググッて直ぐに分かる程度の用語の定義的なことは書かない。あくまでWebサイト制作者側からの観点なので、ブラウザ開発関係者からのツッコミを歓迎します。広告業界の人には広告業界の人で独自の視点があるかもしれない。あとユーザー側、ブラウザ側を主体にして語るので、サードパーティCookieの送信と言ったときには「ブラウザからサーバーへの送信」のことを指している。
サードパーティCookieにまつわるブラウザの仕様について
10年以上前の話
ファーストパーティCookieとサードパーティCookieの区別が無かった。Webサイトに埋め込んだ小さな画像によってCookieをセットして、ドメイン間を跨ってユーザーの行動をトラッキングしアクセス解析や広告に使用するということがプライバシー上の問題となり、このような使い方を抑制できるようにブラウザ側に、現在表示中のドメイン及びサブドメイン及びPublic Suffix Listやその他の方法で判別される同一運営者によってセットされるCookieと、広告やトラッキングで用いられる画像やjsやフレームなど外部リソースの埋め込みによって第三者によってセットされるCookieをサードパーティCookieとして区別するようになった。
ファーストパーティCookieとサードパーティCookieを区別するに当たっては、さらにサードパーティCookieの、受信と送信を区別する必要がある。もし、あなたがgoogleのサービスを使っているとして、google.comのCookieはファーストパーティのCookieとして受け入れられる。受け入れなければログインが必要なサービスが使えなくなるのが自明である。しかしGoogle以外のサイトを閲覧しているときに、ページ内に埋め込まれた、*.google.comの画像やscriptやiframeなどの埋め込みに対してCookieが送られるならば、それはサードパーティCookieである。
web bugによるトラッキングが問題になった頃の楽観的な認識であれば、単に該当ドメインのCookieを拒否することでブラウザにCookieが保存されないのだから、送信も行われない、我々のプライバシーは守られる、ということであった。しかし今日現在、多くのログインユーザーを抱えるような大手サイトが、外部ドメインに対して画像やscriptタグやiframeを埋め込むようなパーツをログインCookieを保持しているドメインを使って配信するという行為が広く行われており、副作用として、ドメインを跨ったWeb履歴の記録を行うことが出来る(実際にやっているかどうかはさておき)という状況が発生している。つまり、多くのログインユーザーを抱えているサービスが、外部埋め込みのパーツを提供すると、ファーストパーティCookieとしてセットされたCookieが、サードパーティCookieとして送られるという問題が起きる。そうやって設定されたCookieは、サイトの機能上必須のものなのか、トラッキングのために用いられているのか、あるいはその両方なのか、区別が曖昧になっている。
古くからブラウザには「Cookieを受け入れるかどうかの設定」やプライバシーを重視する設定にしているユーザーに対しては「Cookieを受け入れるか毎回ユーザーへ確認する設定」が存在していたが、10年前に「サードパーティCookie」という区別が出来て以来、受け入れたCookieを「文脈によって送ったり送らなかったり」する必要が出てきている。しかしブラウザによっては、このあたりの実装がまちまちで「サードパーティCookieをブロック」することが、受信のみブロックする設定であったり、送信もブロックする設定であったりする。
Firefox
- bugzillaで歴史を調べることが出来る。
- Firefox3以降で読取もブロックするように変更された
- http://forums.firehacks.org/l10n/viewtopic.php?p=8256
- サードパーティCookieはデフォルトブロックにしろ(2006-) https://bugzilla.mozilla.org/show_bug.cgi?id=324397
- 殆ど合法的な用途はありません → 正規のサイトをぶっ壊すのでデフォルトでブロックできません
- 動かないサイトが出るからブロックしてても送信するように戻せという話(2008-) https://bugzilla.mozilla.org/show_bug.cgi?id=417800
- localStorageもサードパーティCookieの設定見てブロックしろという話(2009-) https://bugzilla.mozilla.org/show_bug.cgi?id=536509
- http://support.mozilla.com/en-US/kb/Disabling%20third%20party%20cookies
Safari
- デフォルトでサードパーティCookieをブロックすることが知られている
- http://www.apple.com/jp/safari/features.html「あなたのウェブアクティビティに関する情報を収集して販売するために、あなたがアクセスしたサイトによって生成されたCookieを追跡する企業があります。Safariは、このような追跡Cookieをブロックするように設定された最初のブラウザで、あなたのプライバシーをしっかり保護します」とある
- iframeを埋め込んだだけではCookieを保存しないが、iframe内で画面遷移が発生した場合、サードパーティのCookieが受け入れられてしまう。
- そのためデフォルトの設定を変更しなくても、おそらくdoubleclick.netなどの広告Cookieが保存されることになるだろう。
- また、保存済みのCookieは全てのCookieをブロックしても送信される
- SafariにとってCookieのブロックとは「サーバーから送られてきたCookieを保存するかどうかの設定」で、既に保存したCookieを送信するかどうかを制御することが出来ない
Opera
- 10.50で一瞬、サードパーティCookieのブロックがデフォルト設定になった。
- 10.51で元に戻された http://jp.opera.com/docs/changelogs/windows/1051/
- ログイン出来ないサイトが生じたため、と説明されている
- opera:configでは内部的には9段階の設定項目になっている。
- http://jp.opera.com/support/usingopera/operaini/ Enable Cookies参照
- 11.52で試したところ、サードパーティCookieをブロックしても、画像やjsでのCookieセットをブロックするだけで、iframeでCookieをセットすることができる。
- Cookieを無効化しても保存済みのCookieは送信される。Safariと同等。
Netscape
- Netscape7でP3P対応が進められていたが、Firefoxには取り込まれなかった。
- http://news.mynavi.jp/news/2002/09/18/08.html
まとめ サードパーティCookieの設定
ブラウザ毎に見ると
- IE6以降 : デフォルトでブロックしてP3Pという抜け道用意
- Firefox, Opera : デフォルトでブロックしたいけど動かなくなるサイトが出て困るのでブロック出来なかった
- Chrome : ブロックされない。ブロックすれば送信もブロックされるように最近変わった。
- Safari : デフォルトでブロックするけど送信はするという穴を残す
- Netscape : 終了した
デフォルト設定
MicrosoftとP3Pに対応しなかった他のブラウザの関係
- P3PのコンパクトポリシーがIE6と共にサポートされた。
- http://msdn.microsoft.com/ja-jp/library/ms537341(v=vs.85).aspx
- Netscape7でも不完全ながらサポート http://news.mynavi.jp/news/2002/09/18/08.html
- FirefoxはP3Pサポートをやめた http://en.wikipedia.org/wiki/P3P#Criticismshttps://bugzilla.mozilla.org/show_bug.cgi?id=225287
IEがP3Pコンパクトポリシーをサポートした時、P3Pコンパクトポリシーが定義されていれば問答無用で受け入れてしまうというデフォルト設定を採用した。その結果、今では「我々はP3Pポリシーをサポートしない、我々のプライバシーポリシーはこちら」といったP3Pヘッダが使われるなどしている。それでもIEは何の警告も無くCookieを受け入れる。
本来目指していたビジョンは、機械的に読み取り可能なP3Pポリシーを使ってユーザー自身のプライバシーポリシーと、サイト側のプライバシーポリシーを比較し、必要に応じて人間に読み取り可能なポリシーを提示して、Cookieを受け入れるかどうかユーザーが判断できるというものだった(という認識を持っている、当時のニュースでもそのように報道されている)。IE以外のブラウザは、P3Pサポートに追随をしなかったので、実質的にIEにCookieを食わせるためのおまじないとして形骸化してしまっている。
Microsoftにとっては、P3Pコンパクトポリシーに対応することで、自分たちのサービスでは堂々とサードパーティCookieを使用することができるようになった。他のブラウザにとっては「P3Pをサポートしないまま、サードパーティCookieをデフォルトでブロックする設定」にしたならば、Microsoft提供のサービスや、その他P3PポリシーによってサードパーティCookieが使えることを期待しているサービスが使えなくなってしまう。Mozillaは名指しでサードパーティCookieを無効化するとMicrosoftのサービスが使えなくなると書いている。SafariはMicrosoftのサービスが使えなくても構わないと思ったのか、サードパーティCookieをブロックする設定を採用した(ただし送信はする)。「safarihotmail使えない」などで検索すると分かるだろう。
ブラウザ側からすると、プライバシーに配慮したデフォルト設定にするためには「複雑で労力に見合わないガラクタと化したP3Pポリシーに対応するか」「Microsoftやその他サードパーティCookieに依存するサイトが機能しなくなっても構わないとするか」という二択を迫られることになった。
Webサイト側からすると「ブロックしても送信は行われる」「iframe内で遷移させればブロックされていても保存される」といった不具合だか仕様だか分からない抜け道を利用して、Safariで動作するような配慮をしてきたり、P3Pコンパクトポリシーを利用しつつ、動作しなかったらとにかくCookieをブロックする設定を解除するように案内をすることで、サードパーティCookieに依存したサービスを作ってきた。結局Safari以外のブラウザは互換性を重視し「デフォルトで全てのCookieを受け入れる」という設定を変えることが出来なかった。
重要なポジションに居るSafari
サードパーティCookieがデフォルトでブロックされるSafariは「ブロックするけど送信はする」という仕様によってたまたま動いているサイトが多いというだけの状態である。もしSafariが「送信もブロックする」というポリシーを採用したら、ログイン済みのiframeや画像やjsを埋め込むことに依存しているサービスは、SafariとiPhoneで動作しなくなることになる。Safariはともかく、iPhoneはモバイルにとって結構なシェアであるし、ブラウザの設定変更を促すのも難しいだろう。サイト毎に有効にする機能も存在していない。
Appleは「追跡Cookieをブロックする」「あなたのプライバシーをしっかり保護します」と明言しているので、サードパーティCookieをブロックするというデフォルト設定自体が変更されることは、まずないだろう。現状、SafariはサードパーティCookieの送信をブロックしていない。ファーストパーティとしてCookieがセットされれば、他のドメインではそれが追跡Cookieとして機能する。あなたがSafariをデフォルト設定で使っていても、ある程度普通にインターネットをしていれば、doubleclick.netのCookieがセットされることになるだろう。
サードパーティCookieの送信が有効であることによって生じるセキュリティ上の問題
サードパーティCookieが有効であることによって発生している問題が多くある。それはCookieによって認証された状態で他のドメインに埋め込まれることによって、ユーザーが意図しない情報の漏洩が発生したり、操作が行われたりするという問題だ。この手の問題は、ブラウザ側でもリスクが軽減されるように修正がされることも多いが、ブラウザ側で対応すべき問題なのか、Webサイト側で対応すべき問題なのかが曖昧になっている。クリックジャッキングはWebサイト側での対応を必要としたため、対策がされていない大半のサイトが危険に晒されている状態になっている。
- WebサイトにCSRF脆弱性があった場合、画像やscriptタグやiframeで攻撃URLを埋め込むことでユーザーに気付かれずに実行することが出来る
- WebサイトにXSS脆弱性があった場合、iframeで攻撃URLを埋め込むことでユーザーに気付かれずに実行することが出来る。
- フィッシングサイトにログイン状態のiframeを埋め込み、ユーザー名やアイコンなどを表示する事ができる。これによってフィッシングの成功率あがる。
- CSSを使って透明にした状態のiframeを埋め込むことで、クリックジャッキングの問題が発生する。
- 未ログイン状態であれば想定される被害は軽微になる、ということを過去に書いた http://d.hatena.ne.jp/mala/20090306/1236341606
- 画像のクロスドメイン読み込みや、WebGLでのクロスドメインテクスチャなどの問題
- 本来データとしては読み込めない画像を読み込めてしまう問題であり、外部リソースを読み込む際には認証情報を送らないというポリシーによって影響を軽減できる
- JSONハイジャックの問題
- HTTPレスポンスの差異によってログイン状態の判別が出来る問題 http://hacks.mozilla.org/2011/02/an-interesting-way-to-determine-if-you-are-logged-into-social-web-sites/
- 画像やjsのレスポンスで使ってるサービスを判別することができてしまう
もちろん、Cookie以外で認証がかかっているケースもあるので、ブラウザ側での対策も取られなければならないのだが、
- ユーザー毎に固有のレスポンスを返すようなURLに対しては、アクセス制限をかけた上で
- リソースが外部ドメインに埋め込まれて参照された際には「認証情報を送らない」=「サードパーティCookieを送信しない」
というシンプルなルールで、将来に渡って、この手のsame origin policyを突破するバグによる影響を軽減することができる。
特にログイン状態の判定、ログインしているかどうかに応じてステータスコードが変わるもの、応答時間が変わるものなどまで含めると、Webサイト側では殆ど対応のしようがないだろう。多くのWebサイトはログイン済みの状態で外部サイトに埋め込まれることを想定していないし、必要ともしていない。サードパーティCookieの送信を必要としている一部のサイト、ドメインにまたがったトラッキングを行なっている広告やアクセス解析、ログイン状態を必要とするウィジェット・ガジェット・ブログパーツと呼ばれるもの、ダメな仕組みのシングルサインオン、などのために、ブラウザはデフォルトの設定を変更することができないし、サードパーティCookieの送信を必要としない大多数のサイトのユーザーが潜在的な危険が大きい設定でインターネットを利用し、被害をうけることになる。
Webサイト側からみた問題点
ここまでのまとめ
- サードパーティCookieの設定に関するポリシーはブラウザ毎に異なる
- P3PコンパクトポリシーをHTTPレスポンスヘッダに追加さえしていれば、主要なブラウザ全てのデフォルト設定でサードパーティCookieの送信が行われる
- サードパーティCookieは今でも広く使われているし、ブラウザはデフォルト設定を変えることができない
- ログイン状態で外部サイトに埋め込まれることによって発生しているセキュリティ上の問題が数多くあり、サードパーティCookieの送信をオフにすることで影響を軽減することができる。
- 大半のユーザーはこのような問題に無関心であるのでブラウザをデフォルト設定のまま使うし、デフォルト設定に依存してWebサイトがサードパーティCookieに依存した設計をする。
- 著名なセキュリティ研究者でもブラウザの腐った実装やサードパーティCookieの利用の実態について良く知らない
これは三部構成の記事なので、次の記事に続きます。Part2ではWebアプリケーションにおける利用、外部ドメイン向けの埋め込みパーツでの利用とその問題点について書きます。
↧
サードパーティCookieの歴史と現状 Part2 Webアプリケーションにおける利用とその問題
前回 http://d.hatena.ne.jp/mala/20111125/1322210819の続きです。
前回のあらすじ
といった事情を踏まえた上でWebアプリケーションにおけるサードパーティCookieの利用の歴史について書きます。前提知識の共有が済んだので、ここからはある程度個人的な意見も含まれます。実装面での技術的な内容も含みます。
サードパーティCookieが必要とされてきた歴史
広告のためのトラッキングCookie以外にも、サードパーティCookieに依存したサービスが数多く存在してきた。個人的に把握しているいくつかのサービスについて時系列で述べる。ついでに広告業界の流れについても重要なのを幾つか混ぜる。
2005年
- Netvibes、iGoogleなどのパーソナライズホームページサービスが登場する。
- 「ガジェット」としてログイン済みの外部サイトをiframeで埋め込むものが存在してきた。
- GoogleはP3Pヘッダを使ってログイン状態の外部サイトを埋め込むことが出来ると案内している
- NetvibesはSafariユーザーに対して全てのCookieを受け入れるように案内している
- JSONPが使われ始める
- JSON with Padding http://ajaxian.com/archives/jsonp-json-with-padding
- 関数名固定のcallbackが呼ばれるものから、クエリパラメータでcallback関数名を指定できるものが広く使われるようになる
- MyBlogLogが開始
- アクセス解析サービスで、ユーザ登録することでBlogに誰が訪問したのか分かるサービス。
- 後に米Yahooに買収、日本でも類似のサービスがいくつか出ることになる。
2006年
2007年
- 1月、YahooがMyBlogLogを買収する。
- 4月、GoogleがDoubleClickの買収を進める
- 7月、はてなスターがリリース(七夕の季節)
- 10月、DISQUS埋め込みのコメント欄を提供するサービス、サードパーティCookieによって認証している。類似のサービスが幾つか。
- サードパーティCookieも含めて送受信を許可するように案内している http://gyazo.com/95c71b727abcb50cf664f147812b0119
- 参考 http://docs.disqus.com/help/26/
- 12月、gooがgooあしあとを提供開始 http://itpro.nikkeibp.co.jp/article/NEWS/20071220/289990/
- 12月、米連邦取引委員会がGoogleによるDoubleClick買収を承認した http://www.itmedia.co.jp/news/articles/0712/21/news017.html
2008年
- 3月、Yahoo JapanがYahooログールをリリース。yahoo.co.jpのCookieを使用。足あとが残るのは登録ユーザーのみ。
- 3月、欧州委員会がGoogleによるDoubleClick買収を承認した http://www.itmedia.co.jp/news/articles/0803/12/news016.html
- 6月、Firefox3がリリースされる。
- 8月、Yahoo Japanがインタレストマッチを開始
- 9月、クリックジャッキングの問題が知られるようになる。
- 全てのブラウザ、全てのWebサイトに影響するとしてブラウザベンダーが対応を表明した。
2009年
- 1月、IE8RCがリリース、クリックジャッキング対策としてX-Frame-Optionsが導入される。
- Webサイト側でフレーム拒否のヘッダを出力するというもので、サイト側の対応が必須であった。3月にIE8が正式リリース。
2010年
- 4月、Facebookが外部サイト向けのlikeボタンを提供する http://jp.techcrunch.com/archives/20100421facebook-like-button/
- 9月、mixiが外部サイト向けのmixiチェックボタンを提供する
- 12月、mixiが外部サイト向けのイイネボタンを提供する http://developer.mixi.co.jp/connect/mixi_plugin/favorite_button/get_html_code/
- 似たような機能を続けてリリースしているがチェックボタンはポップアップウィンドウで投稿、イイネボタンはワンクリックで投稿完了するものとなっている http://developer.mixi.co.jp/connect/mixi_plugin/difference_of_mixicheck_favorite/
- イイネボタンは、イイネを押した友人の一覧が表示できるようになっている(サードパーティCookieによる表示のパーソナライズを行なっている)
- イイネボタンはサードパーティCookieを送信しないとエラーが起きて動作しない。
2011年
- 足あと終了ブーム
- 3月、gooあしあとが終了する http://blog.goo.ne.jp/ashiato_01/e/876cfd81489c43363b60ac4f4305624b
- 5月、米YahooのMyBlogLogが終了する
- 6月、Yahoo Japanの Yahooログールが終了する
- 6月、mixiは足あと機能を先週の訪問者に変更する(念のため書くと、他のサービスと違い外部サイト上からmixiアカウントを把握されうるのはmixiにとっては意図せぬ挙動である)
- 6月、Googleが外部サイト向けの+1ボタンを提供する http://googlejapan.blogspot.com/2011/06/1.html
- 7月、サードパーティCookieブロックすると google.co.jp にログインできない状態になる
- https://twitter.com/bulkneets/status/87321175977500672
- https://twitter.com/bulkneets/status/87767649244823552
- imgタグやiframeによるCookieのセットに成功すると期待して、シングルサインオンを設計した場合、ユーザーの設定によっては全くログイン出来ないことになる。
- いつから発生していたのか不明、比較的直ぐに解決されたと記憶している
- 8月、Google Puzzleが公開
- 途中までプレイできるがサードパーティCookieをブロックしているとエンディングが見れない
- https://twitter.com/sh4/status/103803450004996096
寸評
個々のサービスついて色々と思うところもあるが特にこの記事で深く掘り下げたりはしない、把握している範囲で述べているだけなので、これ以上に影響の大きいサービスもあったかもしれない。
- ブラウザの機能追加によって、仕様を設計する段階では想定されていなかったリスクが発生している。
- 攻撃手法がWeb開発者に知れ渡るまでにも時間がかかる。JSON Hijackやクリックジャッキングが知られるようになったのは「ブラウザの実装上そのような攻撃が出来る状態」になってから随分と先のことだ。
- 開発者がどういったリスクが発生するのかを知らずに実装してしまうケースが多々ある。
- 意図せずに足あとを残す(訪問者のユーザーアカウントを特定する)リスクがあるサービスは、近年、機能を変更したり終了する傾向にある。
- 2007年ごろ(はてなスター登場時)、自分は、サードパーティCookieに依存したサービスを作ることで、ユーザーやブラウザがプライバシーに配慮したデフォルト設定を選択することができなくなる、と主張していた。
- 実際にブラウザはプライバシーやセキュリティに配慮したデフォルト設定に変更することが出来なかったし、今もなっていない。
- GoogleはDoubleClick買収以降、サードパーティCookieを積極的に利用する傾向にある。
- ちなみにGoogleはログイン時に P3P: CP="This is not a P3P policy! See http://www.google.com/support/accounts/bin/answer.py?hl=en&answer=151657 for more info."というヘッダを送る
- 誰が望んでこうなったのかと言い切ることはできないだろう。Web業界渾然一体となってサードパーティCookieに依存したサービスを作り、無効化すると利用できなくなったり、不具合に遭遇したり、不便を被ったりする世の中を作ってきた。
Web開発者の多くは、単にブラウザの仕様に合わせてサイトを作っているだけで、自分の作るサイトがブラウザベンダーの意思決定に影響を与えているという自覚が希薄かも知れない。また「悪用されたら対策を考えれば良いだろう」とリリース時には単にspamやイタズラに使える程度であろうと考えていた脅威が、実際にはサービスの性質そのものに関わる問題であり対処のしようがない、と後から気付いた所で手遅れだったりもするだろう。ユーザーに対して「そのようなサービスを使うべきではない」と言った所で、自己責任で片付けられてしまうだろう。サードパーティCookieの送受信に依存したWebサイトを作る(あるいは使う)ということは、大多数のインターネットマニアでもセキュリティオタクでも何でもない普通の人たちがWebを安全に利用することができないという、そういう状況を肯定することに繋がっている。
Web開発者はどうすべきなのか?
- まずWeb開発者は(少なくとも自分が開発に関わるサービスの動作確認をする時には) サードパーティCookieの送信をオフにすることを強く推奨する。ついでにリファラの送信も止めていい。
- サードパーティCookieをブロックする設定にしたFirefoxかGoogle Chromeで動作確認をすれば良い。
- 上で挙げたような「ログイン状態のiframeやJSONを外部サイト上から利用する機能」が動かなくなる、ということを把握していれば、大した不便を感じることは無いだろう。
- ブラウザは不適切なデフォルト設定を修正してこれなかっただけなので、自信を持っていい。IEとSafariを見習うべきである。
- ユーザー目線に近いように「ブラウザをデフォルト設定で使う」というポリシーの人もいるだろう。しかしこれは「本来ユーザーに与えられていた選択肢」を取り戻すためのものだ。
- サードパーティCookieオフでは全く動作しない(ログイン出来ない、表示できない、無限リダイレクトする)ようなものは論外で、回避手段を用意すべきである。
- 足あとを残すサービスは、そもそもが、悪意のある第三者に訪問者のユーザーアカウントを特定されるリスクが伴うことになることを理解すべきである。
ブラウザはこれからどうするべきなのか?
- 2001年とは状況が変わっている、現実問題サードパーティCookieに依存したWebサイトが多くあり、トラッキングCookieを利用したターゲティング広告が広く普及し、その収益に依存したWebサイトが多く存在している。
- (よほどユーザーの関心が高まらない限り) WebブラウザがデフォルトでサードパーティCookieをブロックするということが現実的にありえないという状況になっている。動作しないサイトが出てきて文句を言われるためだ。
- Do Not Trackの策定によってプライバシーを気にする人、トラッキングされたくない人はDNT: 1を送ればいいじゃん、という風潮になりつつある。
- しかしDo Not Trackヘッダでは「ログイン状態で外部サイトに埋め込まれることによって発生している諸々のセキュリティ上の問題」が全く解決しないままである。
サードパーティCookieが無効でも動作するようにするにはどうすればよいか
- 今からサービスを作る人は、単にサードパーティCookieを無効化して動作確認をすれば良い。
- 現実問題ユーザーはサードパーティCookieを送ってくるので、ログイン状態で外部サイト上に埋め込まれることで発生する諸々のセキュリティ上の問題に対処しなくてはいけない。
- 既にサードパーティCookieに依存したサービスを作ってしまっている場合に、どうすれば良いのかについて述べる。
ダメなシングルサインオンサービス編
ソーシャルボタン編
1. 単純に別windowでlikeなり+1なりスターなり押させれば良い
- 未ログインの場合には、どうせ別windowで認証画面を開く実装になっているのが殆どである。
- 別windowではファーストパーティCookieとして認証Cookieが送られるのだから、何の問題もない。
- クリックジャッキングも防げる。
- ユーザー毎に表示をカスタマイズしたりするのは、諦めるか、localStorageを使う
2. サードパーティCookieの代替手段として、localStorageを使う
- localStorageにユーザーを識別するためのAPI tokenなどを保存しておくことで、サードパーティCookieの代わりに使うことができる。
- localStorageはCookieと違って、サーバーに勝手に送信されることがない。
- 訪問した段階ではサーバーサイドで誰がアクセスしてきたのかを識別せず、ボタンをクリックした段階でユーザーを識別することが出来る。
- 主サービスとCookieを共有しない別ドメインで提供すれば、ログインCookieをトラッキング目的で使っているという疑いを晴らすことが出来る。
- 純粋にlocalStorageとして使われるのか、保存した値がサーバーに送信されるのかはコードを読まなければ判別が付かない。
- ブラウザはサードパーティlocalStorageの利用に対して、ユーザーに対して通知バーを出し許可を求められるようにすべきである。
「全ユーザー共通のレスポンスを返す」ような埋め込みパーツは、この方式で完全に置き換えることができる。問題は「このページをいいねと言っている友人の一覧」など、ユーザー毎にパーソナライズされたレスポンスを出力する必要があるケースだ。幾つか解決手段があるだろう。
パーソナライズドホームページの類
- OAuthを使う例が紹介されている http://code.google.com/intl/ja/apis/gadgets/docs/fundamentals.html#Cookies
- 上記のように、今であればlocalStorageを代替手段として使うことも出来るだろう。
- サーバーサイドでOAuthのプロキシをしなくても、localStorageやpostMessageといったHTML5の機能を使うことで、クロスドメインでのデータの受け渡しは容易になっている。
OAuthによる認可を与えたり、URLにpasswordやAPI tokenを付加するなどの方法が考えられるが、これは、ガジェット機能を提供しているプラットフォーム(この場合はGoogle)がその気になればユーザーのデータにアクセス可能であることを意味する。認証情報を預かっている以上、ユーザーに代わって操作できる状態になってしまうことが避けられない。つまり、プラットフォームが信頼できないのであれば、サードパーティCookieによって認証されたiframeを読み込んで直接操作したほうが安全、ということになる。外部サービスにidとpasswordを預けるよりもログイン状態のiframeを埋め込んだほうが遥かに安全である。
クリックジャッキングのような問題にどう対処すれば良いのか
- クリックジャッキングに対するブラウザベンダの対応はX-Frame-Optionsによってフレーム内表示を拒否するという方法だった。
- 「iframeを使ってログイン状態で埋め込み、確認なしでワンクリックで反映される」という機能を作る以上、クリックジャッキングは防げない。
- ログイン済みのiframeを外部サイトに埋め込むことを前提とした場合、そもそも安全に実装することが出来ない。
- そのような機能を作るなといっても、もう作ってしまった場合にどうすれば良いのかについて述べる。
- どうしても確認なしで実行することに拘りがあるのであれば「勝手にクリックされても、大きな影響がない程度の機能にのみ用いる」というアプローチが考えられる。
取り消しが可能な操作であっても、ボタンを押したことが第三者に伝わるのであれば、それは意図せずにユーザーアカウントを外部から特定可能な脆弱性となる
- クリックした結果が知られるのが「自分のみ」に限定されているなら、意図せずにクリックされても影響は軽微と言えるだろう。単に効率の悪いspamである。
- またクリック結果が知られるのが「友人のみ」でも、早期に気付くことが出来ればワーム的に拡散していくことは防げる。
クリックしたことをWebサイト側からスタイル制御不能なブラウザ側のUIで通知して、取り消し可能にするというアプローチもあるだろう
外部サイトに広く埋め込まれるようなサービスを設計する際にどうすればいいのか
- 外部サイト埋め込みを前提としたサービスは、主サービスとCookieを共有しない別ドメインで提供し、登録ユーザーにだけ使わせるべきである。
- 別ドメインにする理由は単純だ、Web履歴を収集されても構わないと考えているユーザーだけが有効化にすることが出来るからだ。
- 「広告」や「外部埋め込みパーツ」にGoogleやFacebookやYahooなど、既にログインして広く受け入れられているCookieを用いることに、倫理的な問題がある。
- ユーザーは単に提供される便利なサービスを利用するために、Cookieを受け入れたのであって、外部サイトのWeb訪問履歴を把握されうるということについて、正確な知識を持ち合わせていない。
- (実際にやっているかどうかともかく) その気になれば彼らはGoogleFacebook Yahooのユーザーアカウントと紐付けて、外部サイトの訪問履歴を把握することができる。
- 大手ポータルサイトやSNSが、サードパーティCookieに依存した外部埋め込みパーツを提供し、サードパーティCookie無効では動作しない機能を提供してしまっている。
- 単に実装した人が「サードパーティCookieオフで動作確認をしていないマヌケ」である可能性もあるが、意図的にこういったことをやっている可能性もある。
ブラウザの設定変更を促すことについての問題
- サードパーティCookieがオフでも正常に動作する代替手段があるにも関わらず、実装の簡便さのために、サードパーティCookieに依存した手抜き実装がまかり通ってしまっている。
- サードパーティCookieに依存しない実装をすることが一番良いが、そのような変更を行うことが困難な場合は、リスクを周知した上でサイト毎にサードパーティCookieを許可する設定を案内することが考えられる。
- Safariのようにサイトごとに受け入れ設定を変更することが不可能な場合、ブラウザ全体の設定変更を案内する結果となってしまっている。Safariが悪い。
- IE6以降やSafariにおいては、キチンと理由があってサードパーティCookieをブロックするデフォルト設定を採用しているわけだが、ほとんどのサイトがCookieを全て受け入れる設定に変更するにあたってどのようなリスクがあるのかを的確に説明していない。
- DISQUSのように、提供サービスのドメインのみをCookie許可のホワイトリストに入れるよう案内する方がマシである(Optional:の部分) http://gyazo.com/95c71b727abcb50cf664f147812b0119
↧
↧
サードパーティCookieの歴史と現状 Part3 広告における利用、トラッキング、ターゲティング広告におけるプライバシーリスク
前回の続き。なるべく一般人向けに書きます。サードパーティCookieとあまり関係のない話も書きます。
前回までの概要
トラッキング目的のCookieの利用などからサードパーティCookieの利用は問題視されIE6で制限がかけられるもプライバシーポリシーを明示すれば利用できるという迂回手段を用意、しかし今ではP3Pはオワコン化、SafariはサードパーティCookieの受け入れをデフォルトで拒否する設定を採用したが一度受け入れたCookieは問答無用で送信、Mozilla関係者は「殆ど合法的な利用目的はない」と言っていたものの既存Webサイトとの互換性のために変更できず、ブラウザはサードパーティCookieをデフォルトで無効にすることが出来なかった、そうこうしているうちにWebアプリケーションでのサードパーティCookie依存が進み、ますますブラウザはデフォルトの設定を変更することが困難になりインターネットを安全に利用することができない不適切なデフォルト設定が放置されたまま、トラッキング拒否のための仕様としてDoNotTrackが策定されました。そして広告屋さんは何をしているのか。
前置き
自分は直接的に広告システムの開発に関わったことはなく、広告配信ネットワーク側の事情にあまり詳しくない。ここで書くような問題について既に広く知られているのかもしれないし、知られていないかもしれない。少なくとも自分には十分な対策が取られているようには思えないし、世間一般の人々が「問題を認識しつつ許容出来る範囲として受け入れている」という風にも思えない。どの程度のリスクだと考えるのかは人それぞれだが、このような問題に対策が取られないままトラッキングあるいはターゲティング広告が広く用いられていくと、やがてはWeb広告全般に対する信用が損なわれ誰得全損な状況が発生することが懸念される。
大半のユーザーはこういった問題に対して、無関心であったり無理解であるだろう。無関心であることが暗黙のうちに同意した事にはならないし、無理解で仕組みが分からなかったりどの程度のリスクがあるのかについて適切に判断ができない人がヒステリックに反発するのもよろしくないと思っている。技術について理解のある人は、問題のない実装を考えたり、ダメな実装を批判したり、問題意識が低い人が実装をしないよう監視したり、無関心な人を無関心な人として意思決定のプロセスから排除したりしていくことが大事であると考えている。
ターゲッティング広告全般の問題点について
まず最初に行動ターゲティング、地域ターゲティング、属性ターゲティング、インタレストマッチなどと呼ばれる興味関心や、ユーザーの属性情報に基づいた広告全般の問題点についての前提知識を共有する。問題を3つに分ける。
- 1. アドネットワークによってユーザーが意図しないうちに個人情報が収集されている問題
- 2. 広告がパーソナライズされていることにより、どんな広告が出稿されたのかわかれば、その人がどんな属性を持っているのか大まかな推定が出来る問題
- 3. パーソナライズされた広告配信によって、広告出稿者がユーザーの個人情報を取得することが可能になっている問題
ターゲティング広告のプライバシー上の問題が語られるとき1の「アドネットワークによる情報収集」ばかりが問題になり、その結果2と3について、あまり問題視されて来なかったように思われる。それぞれについて軽く解説する。
1. アドネットワークによる情報収集の問題
すでにログインCookieを持つドメインで、外部サイトに埋め込むための機能が提供され広く普及している。彼らは便利なWebサービスを提供する会社であると同時に、広告配信業者でもある。
- Facebookは likeボタンや各種パーツで www.facebook.com ドメインのiframeを埋め込んでいる。
- Googleは+1ボタンにおいて、.google.com を使用している。
- Yahoo! Japanは、広告において .yahoo.co.jp のCookieを使用している。
ちなみに自分は「広告以外の目的」で普及させたlikeボタンや+1ボタンを使って、ボタンをクリックした場合はともかく、表示しただけ収集可能になるWeb訪問履歴を使用してユーザーの趣味趣向の分析や広告配信の最適化のために使うことは、おそらく無いだろうと考えている。理由としては既に広告のターゲッティングのために十分な情報を収集していて、これ以上収集する必要がないであろうこと、表示しただけではノイズが多すぎるだろうこと、さらに加えると、いくら何でも良識のあるエンジニアが止めるだろうと信頼しているからだ。もちろん単なるアクセスログは保存されるだろうし、場合によってはログにユーザー名も残してるかもしれない。
ただし、Googleはコンテンツマッチ広告として普及させたGoogle Adsenseを、DoubleClick買収後に、行動ターゲティング広告(を含む広告配信システム)へと変化させてきたという前科がある。
- http://adsense-ja.blogspot.com/2009/03/adwords.html
- https://www.google.com/adsense/support/bin/answer.py?answer=100557
Googleは2009年以降、Adsense掲載サイトの訪問履歴から(掲載サイトが明示的に拒否しない限り)ユーザーの属性情報を推定するということを行なっている。そのためAdsense掲載サイトに対してプライバシーポリシーの変更を要請している。ある時期までコンテンツマッチ広告であったAdsenseが、サードパーティCookieを使って複数サイトにまたがったトラッキングを行う広告ネットワークへと変化したわけだ。
2. 配信された広告によるユーザーの属性情報の推定が広告掲載サイトあるいは悪意のある第三者から行える問題
コンテンツマッチ広告で「誰に対しても同じ広告が出力される」のであれば、どんな広告が配信されたのか取得をしても大して意味が無いが、行動ターゲティングやインタレストマッチ、オーディエンスターゲティングと呼ばれるような、ユーザー属性に基づくパーソナライズされた広告が出力されている場合、配信された広告の内容からユーザーの属性を推測することが可能になる。
ここで問題とするのは、 広告を掲載しているサイト、または、ユーザーが自由にJavaScriptを書けるようなブログサービスの場合、どんな広告が出力されたのかを掲載サイトから判別することが出来るということだ。
3. パーソナライズされた広告配信によって広告出稿者がユーザーの個人情報を取得することが可能な問題
これは、お金を払って広告を出稿している広告主が、広告をクリックしたユーザーの属性情報を取得することが可能な問題である。
- 例えば群馬県をターゲットにして広告を出したならば、その広告は群馬県に住んでいるユーザーに表示される
- 広告をクリックして遷移してきたユーザーは群馬県民であることが(広告配信システムのターゲティングの精度が高ければ高いほど)強く推定される。
- 男性、女性、あるいは年齢、職業、趣味趣向、収入などに応じたターゲッティングが可能になっている場合、それぞれ高い精度で推定することができる。
現在表示しているコンテンツやサイトに関連がある広告が表示されていて、その広告をクリックしたなら、あなたがその広告に関心を持ったことは自明だが、それ以外の情報、つまり「広告主が単体では知り得なかった情報を使って広告のマッチングを行っている」のであれば、広告主はある程度の精度で広告経由での訪問者の属性情報を知ることが可能になる。女性をターゲットに広告を出せば訪問者は女性が多くなるだろうし、20代をターゲットに広告を出せば20代の訪問者が来る。「その程度の情報であれば不用意に他人に知られようと問題はない」と考える人もいるだろうが、そうでない人もいる。
広告ネットワークは「広告主に個人情報を売るようなことはしません」というだろう。彼らが売っているものは「Webサイトに訪問するユーザーの傾向、統計情報」であったり「指定した趣味趣向・属性を持っているターゲットに対して広告を出稿する権利」であったりする。しかし、実装方式によっては殆ど直接的にユーザーの個人情報を広告主に売る結果になってしまう。
実装上の問題点についての具体的な事例
概要を説明したので、2と3について具体的な事例を挙げる。
- 多くのサービスが同様の問題を抱えていると考えられるので、特定のサービスを貶めるような意図はない。
- また推測可能な個人情報を問題がない範囲に留めたり、利用規約や広告主の審査によって、悪用されないようにしているかもしれない。
実装上の問題 2の問題について YahooやGoogleの場合
Yahooのインタレストマッチにおいて、配信された広告がグローバル変数として取得可能な様子 http://gyazo.com/a16c39a01a625236c666c4720b1a378e
Google Adsenseは基本的にiframeを使っているが、大口顧客向けのJavaScriptで配信しているタイプのものがあり、同様に出力される広告をJavaScriptから取得することが可能になっている。コンテンツマッチ以外で配信されているものは、ユーザーの趣味趣向に応じた広告であると推測することが出来る。
今後、ターゲティング広告の割合が増えれば
- 属性ごとに表示される広告の傾向を把握する
- ターゲットを罠ページに誘導し、表示された広告を元に訪問者のユーザー属性を推定する
といったことが行えるようになるだろう。
ターゲティング広告 + JavaScriptの問題点
ユーザー毎にパーソナライズされた広告をJSONPあるいは類似の手法で配信すると、配信された広告をJavaScriptの変数として読み取ることが可能になる。この手法は、iframeで表示するよりもサイトのデザインにマッチしたスタイルで広告を表示するなどの目的で、既に広く使われてしまっている。「広告掲載サイトに悪意がなければ、広告が読み取られることは無いのでは?」と考える人もいるだろうが、実際には広告掲載サイト以外からも読み取られることが考えられる。
- 広告掲載サイトを全て審査するのは困難である。自由にJavaScriptを書けるブログサービスなどは特に。
- 現在のブラウザのJavaScript実行ポリシーの性質上、配信される広告を読み取ることが可能になるのが広告掲載サイトだけとは限らない。
- JSONPのアクセス元を制限するのが困難なように、JavaScriptが自分自身から見て、どのページ上で実行されているのかを確実に判断することは困難であるからだ。
- 呼び出し元を制限するような制約を加えたとしても、現在または将来に渡って、location上書き、getter、setterなどを含めて確実に自身がどこから呼び出されたのか判定できる保証がない。
どんな広告が配信されたのかを外部のJavaScriptから読み取り不可能にするには、どのような対策をする必要があるのか?
- 外部のJavaScriptから読み取られることがマズイ内容は、別ドメインのiframe内に出力する必要がある。
- この変更をするためには、既に発行されている広告配信用のタグを、全てのサイトで置き換える必要があるだろう。
あるいは、出力される広告が読み取られたとしても差し支えがないような内容に留めるというポリシーも有りうるだろう。
「どのような広告が配信されたのか」という情報から、例えばユーザーの具体的な氏名であったり、精度の高い住所であったり、Web閲覧履歴を読み取ったりすることはできないだろう。しかし、今後SNSに登録した細かい属性情報を使ったターゲティングが一般的に広く使われ受け入れられ当たり前に使われるようになってしまうと、第三者から勝手に取得できる情報が「その程度ならバレても平気」と言える範囲で収まらなくなる可能性がある。
実装上の問題点 3の問題について Facebookの場合
広告クリックによって広告主からユーザー属性を把握されうるケースの代表例としてFacebookを挙げる。FacebookはFacebookページや外部URLを宣伝することが出来るFacebook Adsという広告配信システムを持っている。Facebookは2011年の9月頃まで、誕生日のユーザーをターゲットにして広告を配信することが出来た。
- 参考: http://www.aimclearblog.com/2011/09/24/facebook-ads-birthday-targeting-gone-poof-away/
- 参考: http://gyazo.com/61cb8e4a49ce36016f23953f81f15325
言い換えるとつい最近まで「クリックすると誕生日がバレる広告を出稿することが出来た」ということだ。ちなみにFacebookがこのオプションを廃止したという事についてのオフィシャルな説明は見当たらなかった。
Facebookの説明を読んでみよう。 http://www.facebook.com/about/privacy/advertising#personalizedads
Facebookが広告主にユーザー情報を開示することはありません(ユーザーが許可を与えた場合は除きます)。
広告主がFacebookで広告を作成すると、場所、年齢・性別、いいね!、キーワードなど、Facebookが受け取る情報や弊社から提供できる情報にもとづいて広告のターゲットを設定できます。たとえば、日本在住の18歳から35歳までのサッカーが好きな女性をターゲットに指定することができます。
広告をクリックしたならリンク先のサイトには、訪問者が広告のターゲットとして設定した属性を持っていることが分かる。少し考えれば分かることだし、Facebookもそのように説明をしている。
広告主が広告を掲載すると、広告主が指定した条件を満たす人に広告が配信されますが、広告主にそれが誰かは開示されません。たとえば、上の例では、広告主は広告をクリックした人が日本在住の18歳から-35歳までのサッカーが好きな女性であると推測することができます。ただし、それ以上の詳細は開示されません。
既存の行動ターゲティングや属性ターゲティング広告は「バレても平気な程度の情報のみ用いる」ということで、この問題に(一応の)対処をしてきた。
- Facebookはこの問題を把握しているが、当り障りのない例を挙げて、ユーザーに対して十分な説明を行なっていない、と自分は考えている。
- Facebook広告のターゲティングは、今まで考えられてきた「広告主に知られても問題ないと考えている情報の範囲」を逸脱している。
- ユーザー登録に必要だから、あるいは、他のユーザーとの交流のためにFacebookに登録した情報が広告のターゲティングのために流用されている。
- そのような広告配信の仕組みについて、ある程度認知されつつあるだろう。しかし「広告主が取得可能な情報」について正確に理解することは困難である。
- 実際にFacebookの広告配信画面を自分で操作してみるまで、ここまで細かいターゲティングが出来ることは想像していなかった。
- 誕生日に対するターゲットは問題を認識したからこそ、廃止されたのだろう。しかし依然として誕生日が1週間以内といった指定は行うことができる。
Facebookが挙げている18歳から35歳までのサッカー好きな女性とは、極端に無難すぎる不適切な例だ。実際にFacebook広告がターゲティングに使える情報は http://www.facebook.com/ads/create/から確認することが出来る。一部を挙げると
- 市町村
- 1歳単位の年齢
- 男性か女性か
- イベント: 誕生日が1週間以内、最近転居した
- 家族構成: 婚約中(1年未満、6ヵ月未満) 新婚(1年未満、6ヵ月未満) 子持ち、子供あり(0-3歳、4-12歳、13-15歳、16-19歳)
- 恋愛対象: すべて、男性、女性
- 交際ステータス: 独身、婚約中、交際中、既婚
- 学歴: 大卒、大学生・専門学校生、高校生 (高校生を除いては指定校へのターゲットが可能)
- 勤務先: 特定勤務先へのターゲットが可能
ちなみにこのツールで男性を恋愛対象とする男子高校生が日本で何人Facebookに登録しているかなどを調べることが出来る。200人だった。
- 交際ステータスをターゲットに広告を出稿することも出来る
- 「婚約中」ステータスに対してターゲティングがされている例: http://www.flickr.com/photos/hirose30/6383824537/
- これは適切に使用されている例だが、広告によってはユーザーの予想に反して不用意に交際ステータスが広告主に知られることになる。
問題となるのは、広告の内容が「そのようなターゲティングがされているように推測できない場合」だろう。誕生日をキャンペーンにしつつ、誕生日向けの広告に見えない。特定の性嗜好をターゲットにしつつ、そのような広告に見えない場合、などだ。
- Facebookの「細かすぎるターゲティング」の問題は既に指摘されてて論文になっていた http://theory.stanford.edu/~korolova/Privacy_violations_using_microtargeted_ads.pdf
- が、誕生日をターゲットに出来るというあからさまにクリックしたら誕生日がバレるような広告がつい最近まで出稿できる状況だった。
- このような問題を指摘されてから1年以上かかってるし、誕生日が一週間以内をターゲットにすることは依然としてできる。
- 「特定個人を識別できるかどうか」ばかりが問題になり、広告主が訪問者のユーザー属性を収集することが出来るという点があまり問題視されていない。
- 今までの行動ターゲティングは、行動履歴から推測された属性情報を使っていたが、今後SNSの属性情報を使うのが主流になると、年齢や職業などの属性は今までは「20代」とか「IT系」で済んでいたものが、具体的に「何歳」「どこの会社」といった具体性を帯びることになる。
- 訪問先Webサイトによる興味の推測は「その程度のことしか分からなかった」というのが「訪問者の属性がある程度ボカされて、バレても平気な程度に収める」という効能をもたらしていた。
- Facebookのような個人情報を握っている企業は、細かいターゲティングが出来ることを「強み」だと考えてターゲティング広告の根本的な問題点を修正しないままで推し進めてしまっている。
- Facebookがやってるから(同じ事をやらないと負けるから)という理由で、間違った実装をしてはならない、「そのような問題を知りませんでした」と言わせないためにこの記事を書いている。
細かいターゲティングの問題にGoogleはどうしているのか?
Googleは「属性別入札は、対象とするユーザーに広告をより多く表示するための方法で、対象とするユーザーのみに広告を表示する方法ではありません」と説明している
指定した属性をターゲットに広告を出しても、その結果誘導されたユーザーは、必ずしもその属性を持っているとは限らない、ということになる。ただし、一定の確からしさで年齢や性別を推定することは出来るだろう。
- ちなみにユーザー層別入札が可能なサイトには、mixiとニコニコ動画が含まれている。
- 18才未満のみをターゲットにして広告を配信することはできなくなっている http://gyazo.com/88b3740fb4a46a08d0b47ad823c6c043
Googleは以下のように説明する http://www.google.co.jp/intl/ja/privacy/ads/#toc-faq
ただし、人種、宗教、性的嗜好、健康、金融など、機密性の高い情報に基づくインタレスト カテゴリをブラウザや匿名 ID に関連付けたり、インタレスト ベース広告の掲載にそれらの情報を使用したりすることはありません。
なぜインタレストマッチや、行動ターゲティング広告、といった広告は自主規制がなされなければならないのか。収集する情報やマッチングに使う情報を制限したり、興味に基づいた広告であることを知らせるアイコンやテキストを表示すべきとされてきたのか。一つはアドネットワークがそのような情報を収集していることを明示し、ユーザーが望むのであれば拒否の意志を示すことが出来るようにするため。もう一つは「そのような種類の広告である」と明示しなければ、ターゲティング広告全般に反対するユーザーは「一切広告をクリックしない」というポリシーでしか自分の情報を守ることができなくなってしまうからだ。
ユーザーは匿名のままでいられるのか?
- 広告配信ネットワークは「広告主に個人情報を売り渡すことはない」「広告主は個人を識別することができない」という。
- しかし広告を出すからには、最終的に何らかの購買行動に結びつけるのが目的なわけだ。
- 広告をクリックした先のサイトで、既にユーザー情報を登録してログインしているかもしれないし、今後「個人を識別する情報の入力を求める」かもしれない。
- どのような条件で広告が出されているのかをユーザーが知らなければ、提供することを望んでいなかったユーザーの属性情報が第三者に知られてしまうことになる。
- GoogleやFacebookを信頼してデータを預けたとしても、そこに広告を掲載している第三者を信頼しているとは限らない。
リンク先が信用できるかどうかを事前に判断することは困難だ。例えば、広告のクリック先でメールアドレスを入力してキャンペーンに応募したとする、住所氏名まではこの段階では信用していないので入力しなかった。「入力したのはメールアドレスだけ」のつもりが、実際には「20-35歳のサッカー好きの女性のメールアドレス」として収集されているかもしれないし、「男性が好きな男性」「女性が好きな女性」「最近誕生日」「最近引っ越した」「群馬県に住んでいる」「特定の企業に務めている」といった情報と共に保存されるかもしれない。Facebookの誕生日ターゲティングがまだ使えた頃ならば「12月2日が誕生日の人のメールアドレス」として収集されるかもしれない。広告を掲載するにあたって、リンク先で一切のアクセス解析を行わず効果測定も行わずログインもせず個人情報も入力しないのであれば、このようなリスクは発生しないが、広告の掲載結果について効果測定を行わないのであれば単に金をジャブジャブ流すだけのカモだ。どのキャンペーン経由で登録した客なのか識別する、といった程度のことであれば、そのような利用方法は全く正当なものだと考えられている可能性もあるだろう。
広告クリック経由で訪問したユーザーに対して「その場限りで」男性であるか女性であるか、どんなターゲット属性経由で訪問したのか、について、無難だと考えられる範囲で、パーソナライズされた表示を行うことはありうるだろう。ただ、ユーザーはそういった属性に応じたランディングページの最適化が「その場限り」なのか、トラッキングCookieを使って今後もその属性を持っているとして識別され続けるのか、容易に区別することができないだろう。
安全なターゲティング広告とはどういったものであるか
ユーザーが安心して広告をクリックできるようにするためには、以下のようなこと考え、複数組み合わせる必要があるだろう。
- ユーザーはアドネットワークに対して、アドネットワークが管理しても良い、広告に利用されても良いと考えている情報の範囲を明示し、必要に応じて自主的に属性情報を提供する。
- 広告主は指定されたターゲットに対して広告を掲載するが、ターゲットの個人情報を取得することが出来ないようにする。
- ユーザーが望むまで、広告主は広告を閲覧またはクリックしたユーザーを特定することができないようにする。
- ユーザーが望むまで、広告主は広告を閲覧またはクリックしたユーザーの趣味趣向、属性情報を取得できないようにする。
- 広告主が訪問者のトラッキングが技術的に不可能なように対策をした上で、広告のリンク先のサイトをプレビューすることが出来るようにする。
- 広告が誘導する先のURLに、広告キャンペーン以外からも一定の流入があることを保証し、どの属性経由で興味を持ったのか判別不能にする。
- どのような条件で広告が掲載されているのか、ユーザーに対して明示し、ターゲット設定に用いられた属性情報を広告主が知りうることを理解した上で広告をクリックする。
行動トラッキングというものは、単に勝手に情報収集されて気持ち悪いとか、そういう気分だけの問題ではない。それを広告に利用する以上、広告主が単体では知り得なかったユーザーの属性情報が受け渡されるということが避けられない(よほどストイックな実装にしない限りは)。だからこそ、ユーザーに対して、どのような仕組みで動いているのか、どういうリスクがあるのかまで含めて説明し、透明性の確保に務める必要がある。広告配信会社は今まで認識して改善を行なってきた問題や、今まさに存在している未修正の問題について、ユーザーに対して十分な説明を行って来なかったと言えるだろう。
まとめ
- ターゲティング広告は、実装方式によっては、悪意のある第三者から訪問者の属性情報を推測することが出来てしまう。
- 広告ネットワークによっては細かすぎるターゲティングをできないようにしたり、センシティブな情報を使用しないように配慮してきたが、Facebookの例に見られるように、そうではないこともある。
- ポータルサイトやSNSに登録したり、広告ネットワークが把握している情報と、ユーザーが第三者に知られても構わないと思っている情報はイコールではない。人それぞれである。
- トラッキングによって収集した情報を、広告のターゲティングに用いるということは、広告主が単体では知り得なかったユーザーの属性情報が広告主や第三者に知られうるということである。
- 特別な配慮無くターゲティング広告を実装すると、広告をクリックした場合にユーザーの属性情報が広告主に伝わることになる。
- 今後、SNSに入力した情報を使った広告の最適化が広く受け入れられ、あちこちで使われるようになった場合、第三者に勝手に知られる情報が「あなたが知られても平気だと考えている範囲の個人情報」では収まらなくなる可能性がある。
- 不適切な実装が放置されたままでは、広告を安心してクリックできない世の中になり、Web業界全般にとって悪影響を与えるだろう。
↧
GoogleがSafariの設定を迂回してトラッキングしていたとされる件について
※この記事の完成度は85%ぐらいなので後で追記します。
- http://webpolicy.org/2012/02/17/safari-trackers/
- http://online.wsj.com/article/SB10001424052970204880404577225380456599176.html
- http://blogs.wsj.com/digits/2012/02/16/how-google-tracked-safari-users/
合わせて読みたい。
一番上のJonathan Mayer氏の記事については純粋に技術的なレポートなので、特におかしなことは書かれていない。元はといえばSafariのCookieブロック機能が狂っている件、それを利用しCookieをセットしている広告会社という技術的なリサーチなので、英語と技術的な内容について抵抗がない人はまず最初に読んだ上で(WSJとの差分について)判断すべき。この記事は技術的な内容を含むので難しいです。内容が理解出来ない場合は難しいということさえ分かればいいです。
WSJの日本語版には
グーグルは特別な暗号を使い、サファリで初期設定されているトラッキング拒否機能に設けられた例外事項を利用する方法で、利用者のコンピュータや多機能携帯電話「iPhone(アイフォーン)」などにクッキー(追跡用の小さなファイル)をインストールしていた。
とある。特別な暗号などと、随分物騒な物言いだが、原文はspecial computer codeだったりする。WSJが書くと、Safariの仕様上の隙をついて、Googleや広告会社がトラッキングをしている(Googleはそれを否定)という論調になっている。素直に読んだら悪事を暴かれたGoogleが言い訳をしていると、そんな風に捉えてしまう人が多くいるのではないでしょうか。この問題がメディアに取り上げられたことは大いに意義があるのだけど、Googleに関しては批判すべきポイントがズレまくっている。問題提起は結構なのだが、何が行われているのかも正確に理解すること無く(理解した上かもしれないけど)、ユーザーの不安を煽りたて、憶測で企業を批判する行為がまかり通ってしまうことのほうがよっぽど問題なのではないかと思う。
ざっくりとした解説
- Googleはディスプレイ広告に対して+1ボタンを表示するかどうかの設定をGoogleアカウントに対して保存している
- doubleclick.netから配信されるAdsenseの広告に対して、その設定を反映させるためにAdsense表示の際に、google.comにリダイレクトして設定を読み取っている
- google.comから設定を読み取った後 doubleclick.net ドメインに遷移して _drt_ という名前のCookieを発行して、読み取った設定を参照できるようにしている。
- この際に、UserAgentがSafariの場合には、iframe内でform送信するJavaScriptを使って、SafariのサードパーティCookieをブロックする設定を迂回していた。
- その結果、既にCookieが保存されている場合は追加のCookie保存も受け入れるルールによって、トラッキング用のCookieも保存されることになった。
その背後にある技術的な背景
- SafariはサードパーティCookieをデフォルトでブロックすると謳っているが、Webサイトとの互換性のために「保存済みCookieについては送信を行い」「いくつかの条件でサードパーティCookieを受け入れる」
- 既にCookieが保存されている場合は追加のCookieも受け入れるという挙動にしたのは Appleのエンジニア https://bugs.webkit.org/show_bug.cgi?id=35824
- form送信でサードパーティCookieブロックの設定を無視する点についてバグとみなして修正したのはGoogleのエンジニア(Safariにはまだ反映されていない) http://trac.webkit.org/changeset/92142
事前に持っていた認識
- SafariのサードパーティCookieブロックはザルなので、トラッキングCookieが意図せずにセットされてしまうことがある。
- GoogleはAdsense表示の際に、隠しiframe内でgoogle.comを参照するということを行なっていた(去年から)
- これを知った時の自分の考えは「おそらくGoogleアカウントに保存されている広告関連の設定を読み取っているのだろう」ということ
WSJの取材後に行われたこと
Google行った対応はどういう意味を持つのか
ディスプレイ広告におけるGoogle +1ボタンの仕組み
- Googleのディスプレイ広告に +1ボタンを表示することが出来るようになった http://adsense-ja.blogspot.com/2011/09/1.html
- ユーザーから見て+1ボタンを表示するかどうかは「+1 personalization on non-Google sites」 の設定が反映される https://plus.google.com/+1/personalization
- 同時期に、Adsense表示の際に隠しiframeでgoogle.com/pagead/drt/uiへ遷移しているのが確認されている
- Google→ doubleclickへのリダイレクト時に、doubleclick.netドメインに_drt_ cookieが設定される。この際にクエリパラメータにpli=1が付いていると広告に対する+1ボタンが有効化され、以降の広告表示の際に反映される。
- 別のブラウザを立ち上げ、同じGoogleアカウントにログインし、+1ボタンに関する設定を変更しても、その場で反映されることは無かった。
このことから、自分は以下のように推測するだろう。
- その人が確かに自分の意志で+1ボタンを表示する設定を選択したのかを確実に判別するために、Googleのログイン機構を使ってdoubleclickにリダイレクトをしている
- もしDoubleClick側で_drt_に保存された文字列からGoogleアカウントの情報を参照できるのであれば、+1ボタンに関する設定が、その都度反映されてもおかしくないが、そのようにはなっていない。
- なので、_drt_ は純粋に広告に関する設定を一時保存するためのCookieであると(自分はGoogleをある程度信頼しているので)考えている
- Cookieに直接設定を保存する選択肢もあっただろう。plusone=1というような。
- DoubleClick側でDoubleClick cookieにGoogleアカウントを関連付けていない、ということを証明することは難しい。
- なぜならGoogleがサーバー側で何をやっているのかは、ユーザーからは分からないから。
Safariにおけるワークラウンド処理に意味はあったのか?
Safariのデフォルト設定では、doubleclick.netドメインに対して「+1ボタンを有効にしているかどうか」の設定を反映させることが出来ない。なので、form送信にするというバッドノウハウを使用した。その結果、意図せずに「トラッキング目的のcookieもセット可能な状態になった」これがGoogleの言うところの「予期せぬ挙動だった」ということ。
form送信を使用しなくても、doubleclickのcookieがセットされるという状況は発生する。
- Safariの開発メニューでUserAgentをFirefoxに変更する
- Ads Preferences Managerを開く。何回かリロードしてもDoubleClick idがセットされないのを確認する。(doubleclick.netに一時的なcookieが保存される)
- Google Adsenseを掲載しているサイトを適当に訪問する。
- DoubleClick idがセットされているのを確認する。
この「form送信にするというワークアラウンドと無関係に」どのみち一度でも広告をクリックしたり、Ads Preferences Managerを訪問するなりすれば、ファーストパーティCookieとしてDoubleClickのcookieがセットされ、トラッキングされる状態になる。
これが、WSJ曰く
グーグルがインストールしたクッキーは一時的なもので、12〜24時間で効力を失う。しかし、ときには幅広くトラッキングされてしまうこともあった。サファリの技術的な「癖」でクッキーが1つでもインストールされると、簡単にほかのクッキーがインストールされるようになってしまうからだ。
はいはい、じゃあこの挙動を知っていたWeb技術者だけが石を投げて良いですよ、ということになる。GoogleはSafariに対して「トラッキング目的でない(Googleの主張)」Cookieをセットするためにフォーム送信というバッドノウハウを使ったが、批判を受けたため今度は「トラッキングCookieをSafariにセットしないために」Safariを特別扱いして、Safariの場合だけCookieが有効かどうか判別するtest用のCookieすら送らないようになった。そうしないと「広告Cookieをブロックしてるはずなのに、いつのまにかdoubleclick cookieがSafariに設定されている」という状況になってしまうから。
というわけで整理すると
Appleの取れる対策はどういったものがあるのか
Safariの挙動については以前書いたとおり。
http://d.hatena.ne.jp/mala/20111125/1322210819
デフォルトで「サードパーティCookieをブロックする」と謳っているSafariだが、抜け道を作っておかないとSafariのデフォルトの設定では動作しなくなるWebサイトが多く発生することになる。Appleは「阻止すべく取り組んでいる」と表明しているが、Safariのこの挙動は、最早、副作用なしに変更することはできない状況になっている。これは単なる欠陥という話ではないし、ソフトウェアのバグというものは、副作用なく不具合だけを修正することが出来るとは限らない。Safariの挙動が不適切だと思うのであれば、サードパーティCookieに依存したWebサイトを作ってきた開発者も非難されなくてはいけない。(Facebookのlikeボタンとか)
Appleの取れる対策はいくつか考えられるだろう。
- 1. 何も変更を加えずにトラッキングを行う広告会社を非難
- 2. 今さらながらP3Pをサポート
- 3. 全てのCookieを受け入れた上でDo Not Trackをデフォルトで有効
- 4. サードパーティCookieの送信もブロックする設定を追加で作る
- 5. デフォルトでサードパーティCookieの送受信をブロックした上で、ホワイトリスト提供(Apple認定 or ユーザー設定)
- 6. デフォルトでサードパーティCookieの送受信をブロックした上で、動作しなくなるサイトには修正を求める
- 7. フォーム送信の際にブロックするポリシーが無視されるという部分のみ修正(likeボタンや+1ボタンの問題は放置)
ブラウザ全体の傾向としてはデフォルトの挙動は「Cookieは全て受け入れる」「プライバシーを気にする人はDo Not Track」ということになるだろう、と予想している(Firefoxの辿った道)
Safariについては、1を行いつつ、4,5,7あたりに落ち着くのではないかと予想している。
Googleのプライバシーポリシー変更にあたってメディアが注視すべきポイントはどこなのか?
- Adsenseで使っているdoubleclick.netのCookieは「個人を特定しない」ことをポリシーとして、Web履歴の収集と、それを使った趣味趣向属性の推測を行なっている。
- これはDoubleClick訴訟の影響があるためで、別経路で入手した個人を識別可能なデータとのリンクが制限されている。
- にもかかわらず、Ads Preferences Managerでは、doubleclick.netからgoogle.comへのリダイレクトによって、doubleclickのcookie情報がgoogle.comに受け渡されている。
- そして、Adsenseにおいては、google.comからdoubleclick.netに対して「Googleアカウントに保存されている設定情報」を受け渡している。
- ここで _drt_ cookieから参照可能になるGoogleアカウント情報がどのようなものであるのかは、ユーザーからは検証のしようがなく、透明性は無い。
- Jonathan Mayer氏のアップロードしているGoogleの資料からその役割を知ることが出来る https://twitter.com/#!/jonathanmayer/status/171347730046787584
google.comとdoubleclick.netのCookie交換は、気安く行われて良いものではない。なぜなら、個人を特定しないことを条件としてGoogleはAdsense経由で訪問者のWeb履歴を収集し、趣味趣向や属性を判別し、広告に利用しているからだ。Googleは個人を特定しないdoubleclick.netの「匿名のWeb履歴情報」と、Google利用規約に同意をしてユーザーの許可を得た上で有効化されたgoogle.comが持っている「検索履歴機能、Web履歴機能」を持っている。これらは似て非なるもので、どうせ「Googleには個人情報を集められまくってるのだから」といって同一視して良いものではない。今まで「個人を特定されることは無いから」として許容されてきたものが、ある日突然Googleアカウント(SNSとして利用しており実名登録、詳細なプロフィールが入力されている)とリンクされることになりました、といったら、それは世間に受け入れられるものではないだろう(少なくとも自分は嫌だ)
なので、Googleの「お客様の同意なしに、DoubleClick Cookie情報を、個人識別情報と結び付けることはありません。 」というポリシーがきちんと守られているのかを監視しなくてはいけないし、DoubleClick Cookie情報を、個人識別情報と結び付けているのではないかと、疑いがかかるような不適切な実装は非難されなくてはいけない。
しかし、自分がGoogleの立場であるならば、このようにも考えるだろう。
- 匿名化されたGoogleのidを受け渡して、広告に関する設定や、ユーザーが広告に使っても良いと許可したプロフィール情報や、本人や友人が+1を押した広告の一覧などに「限定して」アクセスできるようにする。
- 直接的にGoogleアカウントをDoubleClickと紐付けるのは「ユーザーの許可を得た上で」行わなければならないが、個人を特定できないようにしたうえでGoogleアカウントの情報を参照することは制限されないのではないか?
- AdsenseにGoogleアカウント情報を使うことで、どの程度の広告の精度向上が見込めるのかのテストをし、結果がよろしかったらユーザーに対して透明性の確保と選択の自由を与えた上で広く有効化しよう。
http://support.google.com/adsense/bin/answer.py?hl=ja&answer=187844
また、ページにアクセスしたユーザーには、そのユーザーのソーシャル コネクションが +1 した広告が表示される可能性が高くなります。
とあるので、既にそういったことが行われていると考えても良いかもしれない。
ユーザーの反発が大きければ、そもそもこういうことは出来ないよね、ということになるし、その結果リアル人格に基づいたターゲティング広告のほうが実は効果的であって市場の選択の結果Facebookに惨敗する結果になっても仕方ない。FacebookはFacebookでリアル人格に基づいたターゲティング広告にどういったリスクがあるのか、周知されなくてはいけないだろう http://d.hatena.ne.jp/mala/20111202/1322835191
FAQ
- 結局何が起きていたの? → 1.Googleがトラッキング目的ではないCookie(_drt_)をセットしたら 2.Safariの仕様が原因でトラッキングCookie(id)もセットされた
- Googleはこれを意図していた? → 1は意図的に行った 2は予想外だったと主張している
- 最終的にトラッキングCookieをセットするため計算づくで行われた可能性は? → 可能性だけならなんとでも言えますが、そんなことをする必然性は薄いです
- どういう影響があったのですか? → Safariユーザーのうち、広告をクリックしないユーザーに新規にトラッキングCookieがセットされる確率が上がりました。
- 以前からSafariにトラッキングCookieはセットされていた? → 元々、広告を一度でもクリックすればトラッキングCookieがセットされ、維持されることになっていたでしょう
- 他の広告会社については → トラッキングCookieをセットする目的でやってるかもしれませんが、興味が無いので詳しく調べていません。
ブラウザの仕様と倫理的問題
- Safariはトラッキングを防止してくれないのですか? → 受信済みCookieの送信をブロックしないので一度Cookieがセットされれば以降はトラッキングできます。
- GoogleはSafariを特別扱いしていた? → していた。UserAgent(ブラウザ名)で判別。今は逆にトラッキングCookieをセットしないように特別扱いしている。
- なぜSafariを特別扱いする必要があったのか? → +1ボタンをユーザーが明示的に有効にしてもSafariでのみ動作しないことになるから。
- サードパーティCookie拒否してるのに保存する行為がそもそも問題では? → ユーザーが同意の上で有効化してるので https://twitter.com/#!/bulkneets/status/171665462197895168
- サードパーティCookieの受信が完全に禁止された場合は? → 設定変更やGoogleの適当なページ開いた時にdoubleclick.netにリダイレクトしてセットすることもできます。同じ事が面倒な手段で行われる。
- サードパーティCookieの送信が禁止された場合は? → Cookieを全て許可にしてください or 動きません、仕様です、と言うでしょうね
- AppleはSafariの問題を把握していたのか? → WebKitの関係者はずっと昔から知ってるはずです。
- Safariの問題は仕様なんですか欠陥なんですか? → Webサイトとの互換性を損ねないために、問題を把握しつつ修正が行われなかったり、Cookieの受け入れを緩和したりする場合があります。
- 他のブラウザはどうなってますか? → 例えばサードパーティCookieをブロックしても「送信」が行われる問題は、Firefoxはバグとみなして修正を行なっています。
- Opera最強伝説 → Operaも適切にサードパーティCookieを拒否することが出来ません。以前書いたことがあるので読んでください http://d.hatena.ne.jp/mala/20111125/1322210819
_drt_ cookieについて
- _drt_ という名前のCookieは何に使われているの? → 少なくとも、ディスプレイ広告(画像使った広告)に+1ボタンを表示するかどうかの設定に使われています
- _drt_ cookieはトラッキング目的のもの? → 違うと思います。DoubleClickのトラッキングは "id"cookieで行われています。
- _drt_ cookieは+1ボタンを表示するためだけのもの? → 違うと思います。それならランダム文字列にしないでplusone=1でいいからです。
- じゃあ結局何の目的でどういう風に使われてるの? → Googleが積極的に情報を公開しなければ、外部からは推測しかできませんし、内部でGoogleのidと紐付いていてトラッキングに使われている可能性だってあります。もしもそういったことが行われているとすれば問題なので「そもそもユーザーから見て何が行われているのか検証できないような、疑いがかかるような実装は避けるべき」で「FTCが調査するのも良いだろう」と考えていますが、憶測に過ぎないことをメディアが断定的に語って批判するのは避けるべきだと考えています。
IEのプライバシー機能も迂回していたとされる問題
Microsoftが自分たちを棚にあげて便乗してGoogleを批判しており、タチの悪いジョークです。P3Pが最早機能しないことは周知の事実で、ブラウザ関係者であれば尚更です。
補足すると
Wall Street Journalが発端となった過去の問題について
- あとでかく
この件を取り上げた日本のメディア
- あとでかく
まとめ
何が行われていて、どういったリスクがあるのか正確に報道されなければ正しい世論形成が行われなくなります。この件でまともな報道がなされたニュースサイトはほぼ皆無です。
↧
ウォール・ストリート・ジャーナルの過去のトラッキングに関する記事特集
自分が把握していた範囲(と短期間で追加で調べた範囲)なので、他にもあるのかも知れないし、英語圏での反応をちゃんと追えていたわけではない。
リファラについて
2010年5月 Facebook内の広告でユーザーidが外部に漏れていた問題
それに対する対策
サードパーティのFacebookアプリがリファラで外部にユーザーidを漏らしていた問題
2010年10月、WSJ発端
- http://online.wsj.com/article/SB10001424052702304772804575558484075236968.html
- http://jp.techcrunch.com/archives/20101018fear-and-loathing-at-the-wall-street-journal/
- http://www.itmedia.co.jp/enterprise/articles/1010/19/news062.html
実際に不適切な実装ではあるのだけれど、WSJが煽り過ぎたのでテッククランチがカウンター的に問題を軽視する記事を書いた。
その対応
2011年5月 リファラでアクセストークンが漏れていた問題
これはシマンテック発端。
- http://www.symantec.com/connect/blogs/facebook-11
- http://online.wsj.com/article/SB10001424052748703730804576315682856383872.html
これはシンプルに漏れてはいけない情報が漏れていた問題なので、セキュリティホールと呼んでいい。
トラッキングに関するもの
2011年5月 クリックしなくてもトラッキング可能問題
WSJ発端
- http://online.wsj.com/article/SB10001424052748704281504576329441432995616.html
- http://japan.cnet.com/news/service/35003026/
これが翻訳された時に、"「いいね!」や「Tweet」ボタン、クリックされずともサイト訪問情報を送信か--WSJ報道"になってしまう。「送信か」は無駄な疑問形だ。アクセスしてるのだからリクエストが送信されているのは見て分かる周知の事実に決まってる。問題は「送信された情報をサーバーサイドでどのように扱っているのか」だ。仕組み上「誰がアクセスしたのかを識別したり」「likeを押した友人の一覧」を表示する機能があるfacebookのlikeボタンと、誰に対しても同じコンテンツを返す(サードパーティCookieに依存する必要がない)Tweetボタンが同列に扱われてしまっている。
2011年9月 Facebookログアウトしててもトラッキング問題
単にいくつかのCookieを消し忘れていただけ(と推測される)話が、ログアウトしても追跡されると報道がされた。
その後、FacebookとFTC
- http://news.mynavi.jp/news/2011/11/30/049/index.html
- http://blog.facebook.com/blog.php?post=10150378701937131
「ユーザーの許可を得ずに広告主と個人情報を共有した」と報道され、これは実際にFTCもそのように書くからなのだけれど、オフィシャルな説明では「リファラで」という点を明記してる。
The same complaint also mentions cases where advertisers inadvertently received the ID numbers of some users in referrer URLs. We fixed that problem over a year ago in May 2010.
どういった問題が起きているのか
- 「バグでそうなった」ことが作為的に行われているかのように報道されてしまう。
- あるいは「特に気を使わなければそうなる」ことや「ブラウザの問題だよね」ということも、Webサイト側の問題とされてしまう。
- 海外速報記事として日本語の記事が出るタイミングで、細かいニュアンスが不正確に翻訳されてしまう。
- 自前で検証をしないで「WSJの調査によると」と受け売りの報道をしてしまい、事実である部分を無駄に疑問形にしたり、不確定な部分を確定情報として書いてしまったりする。
こういった経緯で「アクセスログが残る」が「トラッキングが行われている」と報道されるようになり、リファラに不用意に個人を特定可能な情報が入っていると、ユーザーに無断で広告主に個人情報を提供している、と報道されるようになった。ユーザーidがリファラに含まれてしまう問題はFacebookとしては解決を図ったが、サードパーティアプリが不適切な実装をしていれば今後も起こりうる。ユーザーが広告をクリックしたときに広告主から見て、そのユーザーがターゲティングに使われた属性を持っていることが分かるが、この問題については殆ど解決していない。
検索ワードとリファラ
リファラはどう扱うべきなのか?
- Googleの検索ワードがサイトに伝わるとして訴えられた話 http://it.slashdot.jp/story/10/10/29/0113228/http://japan.cnet.com/news/business/20422043/
- SSL化にあたって検索ワードがサイトに伝わらなくなる話 http://www.sem-r.com/news-2011/20111020021735.html
検索ワードが訪問先のサイトに伝わることなんて、実際のところ、大多数のユーザーは知らないんじゃないかと思う。それが必要とされてきたからそうなっているわけだけど、Web業界の慣習、常識的に、当たり前に行われていたことでも、それを知らないユーザーにとっては当たり前ではない。
Googleはインスタントサーチで、画面遷移なしで検索ワードを変更できるようにしている。インスタントサーチで検索した場合、リファラで送られないlocation.hash部分(URLの#以降)に検索ワードが含まれることになる。SSLをデフォルトにする前から、本来ならばとっくに「正確な検索ワード」が取れなくなってもおかしくなかったが、わざわざリダイレクタを挟んで、正確な検索ワードをアクセス先のサイトにリファラで取得可能なようにしている。(いやこれは検索結果のクリックログを集計するためのものでたまたまこういう仕様になっているだけですよ、ということもできる)
さて、Googleの検索ワードの場合、インスタントサーチにおいては(本来残らないリファラを意図的に復活させて)Webサイトや広告主がユーザーの動向を把握できるように、意図的に検索ワードを取得できるようにしていると、強く推定できる状態だった。それがSSLをデフォルトにするタイミングで、サイト側には検索ワードを渡さない、広告主には検索ワードを渡す、こういう変更が意図的に行われたのだろう、ということが確認できる。
というような状況も踏まえて、Facebookが「広告主にユーザーidを(リファラで)渡していた」という話は、それも含めて「Facebookの売り」であったのか、単なる実装ミスであるのか、誰が公正に判断できるのだろうか。「そんなのどこもやってるし問題ないでしょ」なのか「バグでしょ(常識的に考えて)」なのか「意図的にやっていたに違いない」なのかは、実際にコードを書く人や「その情報を取得していた人」の感覚が分からないと、正しく推測することが出来ないだろう。少なくとも、オフィシャルな説明においては、広告を表示、あるいはクリックした人が誰だかわかる、なんてことを売りにしたりはしていないわけだ。
個人的な感覚で言えば、Facebookであればそのレベルのプライバシー保護対策が求められるのだろうけれど、「ユーザーidがリファラで漏れる」サービスなんてザラにあるし、対策していなかったとしても「個人情報を第三者に積極的に提供している」かのように非難されるべきだとは思っていない(アクセストークンやセッションidなど秘匿すべき情報がリファラに入るのはマズイ)
情報格差によって起きるFUD
リファラの件もそうだけど、知ってる人であれば当然知っているようなことで大騒ぎ、というのが今後も起きるのではないかと思う。likeボタンや+1ボタンによってログイン中のユーザーがどのサイトを訪問したのか分かってしまう(その情報をどう使うかはさておき)なんて話は、技術者であれば誰でも知ってる話だったはずだ。単にアクセスログに残るという話が「トラッキングに使われている」と断定するような報道がなされる。結果何が起きるかというと、
- 一般ユーザー: そんなことは今まで知らなかった、なんてことだ、怖い
- 技術者: そんなことは当然知ってたけど、ニュースになるからには「何か重大な証拠を掴んだ」のだろうと予断を持って記事を読んでしまう。
本来ならば「えっ、なんだそんなことか」と冷静に読まれるべきところが「ニュースになった」という事自体が判断に影響を与えて、正確な情報伝播がなされなくなってしまう。そんなの当たり前に皆知っていたはずの話が、Googleだったら、Facebookだったら「何か邪悪なことに利用されているに違いない」と邪推されてしまうことがある。本来だったら「バグでした」で済む話が、「それぐらい計算して意図的にやっててもおかしくないな」と邪推されてしまうことがある。それがバグなのか意図的にやってるのかは「実装」に詳しい人にしか分からないのだが、実際には判断する能力を持たない人たちが大騒ぎして断罪されることになる。
放置される技術的な問題についてどう対処すればいいのか?
実際に不適切な実装が行われているということについては放置されてしまう。例えば、俺はFacebookやGoogleのような重要個人情報を預かってる企業が、ログイン中のユーザーの外部Webサイトの訪問履歴を取得できてしまう(そしてユーザーからアクセスログがどのように扱われているのかは確認できない)ような機能をデフォルト有効で提供する事自体に問題があると考えているけれど、そういった問題はFTCが立ち入り調査して「違反したら罰金ね」といってそれで終わりだ。
- Facebookのlikeボタンは、サードパーティCookieをオフにすると正常に機能しなくなることが知られている。(ボタンを押したら無限にwindowが開く)
- 誰が訪問したのか関係なく、単にlikeが押された件数を表示するだけであれば、ログイン中のユーザーを取得する必要がない。
- 単に手抜きなのか、Facebookに対してサードパーティCookieを有効にしないと不利益が発生するような状況を意図的に作っているのか、判断が出来ない。
「トラッキングをしている」と言うのであれば、何が行われているのかわからないサーバーサイドでのデータの取り扱いについて、憶測で「信用ならない」というのではなく「具体的な証拠を掴んだり」あるいは、そういった実装にする必然性がないのに「トラッキングも可能になる」ダメな実装を選択している、ということを批判しなくてはならない。で、そういう批判が説得力を持つためには、プライバシーに配慮した代替案として具体的にどういうものがあるのか広く知られるようになり、エンジニアとしての偏差値が50以上であれば誰でも思いつくよね、という状況を作らなければならないのだろう。
まとめ
- 不正確な報道と、それをソースにした翻訳記事によって、元記事における反論や技術的な細かいニュアンスが失われてしまっている。
- 特にタイトルと要約だけ伝えたようなものが独り歩きすると、まるっきり不正確な記事が出来上がってしまう。
- 「疑いがある」というものが、まず「調査によって○○であることが判明した」と書かれ、それに対して「□□は否定している」という体裁で書かれることが多い。
- 技術者が「アクセスログが残る」「技術的にはトラッキングにも使用可能」と表現に気を使っていたところが、likeボタンや+1ボタンがトラッキングに使われるといった報道が平然となされるようになってしまった。
- 不用意にリファラ経由で情報が漏れていた(と推測されるものが) 広告主に個人情報を共有していた、となり、表現に気を使わない個人ブログ等であれば広告主に個人情報を売り渡していた、と伝搬されるようになってしまった。
- とりあえず煽るだけ煽っておけば、FTCが調査してくれるので、結果としてはオッケー、という傾向になっていないだろうか。
- 意図的に行われていることについては「なぜそれが必要とされてきたのか」も含めて適切に報道され、リスクが許容出来る範囲に収まっているのか判断されなければならないだろう。
- 人々は分かりやすいストーリーを求めているのかも知れないが、不確定な情報は不確定なものとして、そのまま扱うことができないものだろうか。
などということを考えている。
↧
ブログパーツやソーシャルボタンの類でアクセスログが残るのは当然だけどトラッキングされるのは当たり前にはなっていない
わたくしは立場上、実装がダメなことにはとやかく言いますがポリシーについてはとやかく言わないことをポリシーとしており、また個人的にも所属組織的にも付き合いがある企業様を痛烈に批判するというのはブーメランとか槍とか鉄砲玉とかソーシャルメディアガイドラインとか飛んできたりしてリスキーではあるのですが、どう見てもアウトだろこれ、と考えるに至りまして筆を取らせていただく次第です。
これ
どう見てもアウトだろ。理由は単純で、そういう目的で設置されたボタンではないし、はてなブックマークボタンが設置されているサイトは、はてなの管理してないサイトなのではてなの裁量でやってはいけないからです。いつから「はてな」は「はてなが管理してない」サイトのログを勝手に使って良いことになったのですか。
はてなの問題
行動情報の取得(個人情報以外)
とか
個人が特定されうる情報(生年月日、メールアドレス、はてなIDなど)は一切収集されません。
とか、いかにも個人情報じゃないから、はてなの裁量で勝手にやっていいみたいなニュアンスが読み取れるのだけど、はてなと言えば管理画面のURLにユーザーidが入ってることで有名なので、管理画面からリファラがあれば、それがはてなid誰々さんだと分かるわけで、当然このように http://gyazo.com/f4729771f4b6ead8ae5717d27166384a /mala/admin に訪問したからにはid:malaさんに違いないという情報がマイクロアドにも送られてしまう。ただし、マイクロアドは、わざわざこの情報を使わないだろう(行動ターゲティングをやる会社にとって個人を特定可能な情報はリスクでしかないから)
そもそも、外部サイトにおいても、URLやリファラに「生年月日、メールアドレス、はてなIDなど」が含まれないことを誰が保証できんの?
- 個人が特定されうる情報は一切収集されません、というが、それは間違いで、収集されることがある。
- 「個人を特定することは出来ません」ではなく「個人を特定することをいたしません」と言うべきだ。
あとこの情報収集しないブラックリスト指定はなんなの?
http://b.st-hatena.com/js/bookmark_button.js
var domains = 'www.toyokeizai.net member.toyokeizai.net excite.co.jp exblog.jp mainichi.jp jp.msn.com *.jp.msn.com itmedia.co.jp bizmakoto.jp atmarkit.co.jp eetimes.jp ednjapan.cancom-j.com ednjapan.com barks.jp www.asahi.com *.asahi.com jp.techcrunch.com japanese.engadget.com jp.autoblog.com celebrity.aol.jp www.nikkei.com *.nikkeibp.co.jp japan.cnet.com japan.zdnet.com builder.japan.zdnet.com japan.gamespot.com www.re-source.jp www.yomiuri.co.jp groupon.jp';
マイクロアドの問題
そもそもなんでマイクロアドは、こんな情報もらって良いと思ってるの?
http://send.microad.jp/w3c/jiaa.html
提供を受ける者の範囲 MicroAd広告アドネットワーク(MicroAdの広告が表示されるパートナーメディアのみとなっております。
いつの間にはてなブックマークボタン設置してるだけでMicroAdの広告が表示されるパートナーメディアになってしまったの?
それともこれは企業向けソリューション( http://www.microad.jp/solution/ ) で、通常のMicroAdの広告とは一切関係なくMicroAdはサーバー貸してるだけで収集された情報について一切関知せずpartnerid=6は、はてなに対する広告配信及びアクセス解析機能を提供してるだけみたいな感じなんでしょうか、それだとMicroAdのトラッキングCookie使ったりMicroAdのページからオプトアウトするのが不自然な気がします。
http://b.hatena.ne.jp/help/bbuttonには
また、この取り組みは「一般社団法人 インターネット広告推進協議会(JIAA)」が定めるガイドラインに遵守しております。
って書いてあるんだけど、提供を受ける者の範囲間違ってるよね。間違っててもガイドライン遵守してることになるの?
そんなことどこもやってるのでは、という誤解
ブログパーツやソーシャルボタンの類で行動履歴が収集されるのは当たり前、と考えてしまっている人がいるようだ。最初からそういう目的であると謳って配布されている広告やブログパーツであるなら分からないでもないが、当初はそういう目的ではなかったのに後から行動履歴が収集されるようになる(しかも他社のサービスのシステム使って)、というのは異例だろう。
単にアクセスログが残るという話と、トラッキングに使われるということは明確に違う。「そのような疑いがかけられる実装をしている」ということが、繰り返し報道されることによって、いつの間にか既成事実化してしまった。メディアはきちんと「アクセスログが残ること」と「トラッキングが行われていること」を区別して報道してください。
ちなみに自分は以前にこう書いた。
http://d.hatena.ne.jp/mala/20111202/1322835191
ちなみに自分は「広告以外の目的」で普及させたlikeボタンや+1ボタンを使って、ボタンをクリックした場合はともかく、表示しただけ収集可能になるWeb訪問履歴を使用してユーザーの趣味趣向の分析や広告配信の最適化のために使うことは、おそらく無いだろうと考えている。理由としては既に広告のターゲッティングのために十分な情報を収集していて、これ以上収集する必要がないであろうこと、表示しただけではノイズが多すぎるだろうこと、さらに加えると、いくら何でも良識のあるエンジニアが止めるだろうと信頼しているからだ。
これを書いた時に、はてなブックマークボタンの事例を全く知らなかったし、はてなには良識のあるエンジニアがいなかった・・・。GoogleもFacebookもトラッキングに使うということを否定している。それをやったら大問題だからだ。
Googleの場合
Facebookの場合
単に「アクセスログが残る」という話だったのに「情報が収集される→トラッキングされる→広告の最適化に使われる」と人々の意識に刷り込まれてしまった。
かつてGoogleがやったこと
Googleが行動履歴を収集しているのはAdsense広告であって、+1ボタンではない。そのAdsenseも以前は行動履歴を収集していなかった。Googleは、Adsenseをコンテンツマッチ広告から行動ターゲティング広告に変更するにあたって「訪問者の許可を取らないといけないからお前のサイトのプライバシーポリシーを変えろ」ということをやった。
これと同等の取り組みをするのであれば、はてなが許可を取らなければいけないのは、ブックマークボタンを設置する人に対してではない、情報を収集される訪問者に対してだ。はてなブックマークボタンを設置するにあたって、あなたのサイトのプライバシーポリシーを変更してユーザーの同意を取ってください、とお願いして回らないといけない。
とはいってもソーシャルボタンの類で当然にユーザー行動履歴が収集されるものなのだと世間一般に認知されるのは業界全体にとってマイナスだと思いますし、同意取って済む話では無いので、今すぐ中止したほうがいい。
まとめ
↧
↧
後付けでトラッキング機能が有効化されることについて、はてなとTwitterの場合
前: http://d.hatena.ne.jp/mala/20120308/1331193381
はてなのその後の話
- http://hatena.g.hatena.ne.jp/hatenabookmark/20120313/1331629463
- 話題になってからの対応が遅い、という人がチラホラいたけれど、別に対応はそれほど遅いというわけでもないと思う。
- これは近藤さんがSXSWというイベントに行っていて日本にいなかったためで、収益にも影響する話なので即断できなかったのだろう。
- こういう時にあとさき考えないで不良社員が勝手に広報したり、勝手に修正しても良いと思う(個人の感想です)
- 公平のため記しておくとHUG Tokyoというイベントで大西さんにおごってもらった(はてなの脆弱性をちょくちょく報告しています)
Twitterの話
- 先日、Twitterが外部サイト上でのボタン、ウィジェットでトラッキングして、それを元にしておすすめユーザーを表示する、という機能をテストし始めた。
- http://blog.twitter.com/2012/05/new-tailored-suggestions-for-you-to.html
- デフォルトでは無効だと思っていたのだけど、ちらほら有効化されているようだ(ヨーロッパ圏を除く、といった具合だろう)
- 広範なWebサイトに埋め込まれているボタン、ウィジェットに対して、後付けでトラッキング機能が有効化されたことになる
- ブログでの告知、ユーザーに対するメールでの案内はあるが、興味がない、読んでいない人にとっては勝手に有効化されている。
実装面のこと
- 俺が気にしているのは、リコメンド機能を通じて非公開のつもりだった情報(例えば特定のサイトを訪問したかどうか)が第三者から知られうるか、といったことだ
- おすすめされるのは "同じウェブサイトを閲覧しているユーザーが頻繁にフォローしているユーザー"
- 表示されるのは同じ趣味を持っているユーザーが「頻繁にフォローしているユーザー」なので、この機能によって、ユーザーの訪問サイトが他人から推測されるということは、まず起こらないだろう。
- ものすごく沢山アカウントを作って特定条件でしか表示されないおすすめユーザーを作る、であったり、他人をトラッキング有効状態にしたアカウントに強制ログインさせておすすめユーザーの傾向から訪問サイトを推測、といった方法は考えられるだろう(しかし得られる情報に対して十分に悪用コストが高いと思う)
- 将来にわたって安全かどうか、アルゴリズム変更されないか、何かやらかさないかという保証はしないし、できない。
- Twitterは過去にIPアドレスを使ってユーザー推薦のテストを行っていて、中止している http://nlab.itmedia.co.jp/nl/articles/1105/24/news035.html
- 「配慮してこうなっているのだろう」と思っていたら実は大して何も考えてなくて、あっさり変更されたりということも良くあるものだ。
登録ユーザーだけか?未登録ユーザーも含めてか?
- https://support.twitter.com/articles/20169942
- 一部のユーザーに関しては、登録したタイミングで最適なおすすめユーザーを表示すると言っている。
- 一般に行われている広告目的でのトラッキングは、Webサイトの履歴を収集するけれど「それが誰なのかは分からない」ようにしている
- 登録前からのトラッキングを行うと「誰なのか分からない状態」から、Twitterに登録した瞬間に誰であるのか把握できるようになる
Twitterに登録する前から、そのユーザーの好みを把握しようとするとなると、ユーザーはTwitterの規約を「まだ読んでいない」し、それを望んでいるのか判別する方法がない(Do Not Trackヘッダで「拒否」は示せる)
Do Not Trackの話
Twitterは、十分に安全な実装だと考えているからこそ、この機能をデフォルトで有効化するのだろう(ヨーロッパ除いて)。で、俺が懸念していることは「Do Not Trackで拒否できるからいいでしょ」といって「勝手にやっても平気(とされている)ことの範囲」が今までよりも広がってしまうことだ。「拒否できるかどうか」ではなく、どんなidでトラッキングされているか、どんな情報がどこに収集されているのか、何が目的か、非公開のつもりの情報が意図せず他人に知られてしまわないかどうか、を気にしなくてはいけない。今まで広く行われてきたことは「個人を特定可能なid + 自社サービス内の履歴を利用」または「個人の特定が不可能な匿名id + 広範なWebサイトの履歴を利用」であって「個人を特定可能なid + 広範なWebサイトの履歴」というパターンは明示的な同意があって行われることだった(GoogleツールバーでWeb履歴機能を有効にする場合、等)
考えなければいけない差異は何か
単純に比較できない(してはいけない)問題なので、ポイントをいくつか整理しておく。
告知可能かそうでないかの問題
- はてなブックマークボタンをサイトに設置するユーザーは、必ずしもはてなのユーザーではない(ボタン設置者全員に現実的な手段で告知不可能)
- TwitterはTwitterのボタン・ウィジェットを設置しているサイトに対しては、同様に告知することが出来ないけれど、登録ユーザーに対してはメールでプライバシーポリシーの変更を告知することができる(到達可能なメールアドレスを入力してくださいという建前で)
はてなの場合、トラッキングされるのははてなの登録ユーザーだけではないし、ボタンの表示領域では告知のしようもない。俺はGoogleがAdsenseでトラッキング開始したときの前例を参考にするならばWebサイト側のプライバシーポリシーを変更してユーザーに周知させなければならないと書いたがそんなものは建前であって実際にそんな世の中になることを望んでいない。ブラウザがP3Pヘッダを見つけて利用目的とオプトアウト方法を通知バー的なもので表示してCookie受け入れるかどうか送信するかどうか、あるいは次回からリクエスト丸ごとブロックするかどうかなど選択可能な世の中が実現していたならば、そんなものは必要なかった。そうはならなかったので人間が読めるようなプライバシーポリシーを目立つところに掲げろなどという馬鹿げたことになってしまっている。人間に読める形式で書いてあっても肝心の人間は読まない。
Twitterのケースはどうだろうか。基本的にはTwitterのボタンを貼り付けてるサイトは放っておいて良いと思う。まだTwitterに登録していないユーザーにとっては、今まで通り「単にTwitterにアクセスログが残る」という認識でいればよく、Twitterに登録しているユーザーに関しては、Twitterのプライバシーポリシーに則って、機能を有効化した場合には集計集約されるということを知っておけばいいからだ。ただし、Twitterに登録していない段階でのトラッキング(Twitterに登録しなければ何にも使われずに10日で捨てられる)をどう扱うべきなのかは分からない。「個人特定が不可能なidでトラッキングするけど、ユーザー登録しない限りは利用されずに捨てられるよ」というパターンでボタン・ウィジェット設置するWebサイト側に何らかの告知が必要なのだろうか(ヨーロッパ圏では必要だ、と言いそう)
利用目的によるリスク評価、広告の場合、リコメンドの場合
広告をクリックした場合に、広告主に対して、広告をクリックしたユーザーの属性が取得できてしまうという問題について過去に書いた http://d.hatena.ne.jp/mala/20111202/1322835191
実装次第では、表示される広告経由で訪問者の属性が推測できてしまう。あるいは行動履歴によって推定されたユーザー情報を確認する機能がある場合、例えばDoubleClick cookieが漏洩すればAds Preferences Manager経由でユーザーの属性情報が直接的に漏洩することになるだろう。
リコメンドの場合でも、不適切な実装をしていたなら、ユーザーの取った行動が間接的に把握できてしまうことになる。
ログインidや訪問先URLの情報を受け取る必然性があるか
- ログイン状態に応じて表示内容を変化させる必然性があるか
- Facebookのlikeボタンのように同じURLに言及している友人の一覧を表示する機能があるなら、ログイン状態を取得する必要がある。
- Twitterのウィジェットはログイン状態に応じて表示内容が変わるといったことがない。表示が変化するのはフォローボタン(フォローしてるかどうかトグルになっている)ぐらいである。
- ボタン・ウィジェットが埋めこまれているURLを収集する必然性があるか
- ブックマーク数を表示する、Twitterでの言及数を表示する、という機能をつけるのであれば、それは見ているサイトのURLを送る必然性がある。
- 「どのサイトに埋め込まれていても同じ内容を表示する」のであれば、埋めこまれているサイトのURLを取得する必然性がない
はてなはマイクロアドへの情報送信にあたってトラッキング用のコードを追加しているし、Twitterも「たまたま取得できる情報を活用しました」ではなく、トラッキング用のコードを追加している(p.twitter.comドメインに送信される)
匿名idでのトラッキングと個人特定可能なidでのトラッキングの区別
だいたい今まで行われてきたのはこんなことだ。
- 匿名のidで、広告掲載サイト、トラッキングコード使用サイトの行動履歴を取得 (一般的な行動ターゲティング広告)
- そのサービスのidで、そのサイト内の行動履歴を取得 (サービス提供者自身によるアクセス解析や、改善目的での利用)
- そのサービスのidで、自社サービスに入力されたプロフィール情報や行動履歴を広告目的につがうが、外部サイトの履歴は収集しない (自社サービス内で十分なデータを集められる大手ポータルサイト等)
- そのサービスのidで、外部サイトの行動履歴を取得するが、ユーザー明確な同意を得て使う(Google Web History、足あと系のブログパーツ)
個人特定可能なidで外部サイトの履歴を取得して、直接的に特定ユーザーの履歴を商品として販売しまくり、といった話は聞いたことがないし、まあそんなことにはなっていない。Twitterは外部サイトの履歴をおすすめユーザーの改善目的には使うが、広告目的には使わないと明言している。
はてながやったことは、悪く言えばユーザーのWebサイト訪問履歴という個人情報を(金目的で)第三者に売り渡した、ということになってしまう。俺の個人的な考えでは、外部サイトへの埋め込みパーツから取得できるログの利用を「はてな自身がやるよりも遥かにマシ」だと思っている。はてなを信用しているとか、信用していないとかの問題ではなく、個人特定可能なidを持っているサービスが、自社サイト外の、広範な外部サイトの履歴を扱うという選択をするほうがリスクだ。それは重大な責任が伴う行為だ。必然的に自社サービスのユーザー、特定のユーザーがどのサイトを訪問したのかを把握できてしまうことになるからだ。どのユーザーがどのサイトを訪問したのか分かってしまうログなど、積極的に捨てるべきだと思う。実際にどちらのほうがリスクが高いのか、低いのかということを考慮せずに(それをどのように判断するかは人それぞれだとは思うが)、形式上、第三者に履歴情報を提供したということが問題視されてしまった。十分な技術的な見識、前提知識がなければ、ユーザーはどちらがマシなのかということを正常に判断できず、感覚・感情で判断してしまうことになるだろう。
まとめ
- Twitterは、Do Not Trackで拒否できますよ、といって「個人特定可能なid + 外部サイトの履歴」を使う機能をデフォルトで有効化してしまった(ヨーロッパ除く)。
- この機能自体には、現状、大したリスクはないだろう。ヨーロッパとかドイツとかで問題になるかも知れないけど。
- GoogleやFacebookが同じことをやるかというと、もっと慎重にならざるを得ないだろう(広告屋でもあるから)
- しかし全体的に、時間をかけて、同意を取った上で or DNTで拒否できますよ、といって「個人特定可能なid + 外部サイトの履歴」が利用されるようになるのは避けられない傾向であるように思う
俺は「個人特定可能な情報を預かるのであれば」広範なWebサイトの履歴を収集できてしまうような、リスクの高い実装は積極的に避けるべきだと思っている(ログインCookie持っているドメインで外部パーツを作らない) そして、個人特定可能な情報を持っている企業が、広範なWebサイト上の行動履歴情報を取得するということは、あくまでユーザーを匿名のまま取り扱おうとしている広告事業者が同じことを行うよりもリスクが高いと考えている。自分は「信頼して個人情報を預けている企業」であるほど、信頼しない、という一見矛盾しているような選択をする。それは、疎結合の方が望ましいという、エンジニア的な美学の話で、それが広く理解されなければ、なるべく自社サービス内でユーザーのプロフィール、行動情報を蓄積して、大量のデータを保有している企業が勝ち続けることになってしまう。自分が最も懸念しているのはそういう話だ。
↧
「Facebookで自分の名前と写真を広告に使えないようにする方法」について
表題の件について、ソース不明の噂話や、意味を理解しないままリスクを誇張して拡散される様子を数日前から見ることができる。放っといて収まるかと思っていたらnanapiが大拡散していた。記事を書いているのはnanapiの社長であるkensuuである。時給800円のバイトかと思ったらkensuuである。
この件についての見解をいくつかTwitterに書いた。
まあ、全くのノーリスクというわけでも無いだろう。
正確に言えば「この設定が意味を持つような不適切な実装をしてはならない」
「表示」するだけならば、広告主や、他の広告ネットワークに対して、あなたのプロフィール画像や表示名に対してアクセスを許可する必要がない。facebook.comのiframeを使って直接Facebookから表示するだけだ。この意味がわからなかったらウェブ系の仕事に関わっているプログラマの人に聞いてみましょう。そのプログラマの人が、自分の言わんとしていることを分からなかったら、無知で無能なクズですので、そのような人間に仕事を与えてはいけません。不適切な実装をし、バグを産み、ユーザーの個人情報を漏洩させる危険因子です。経営者の人は、そのような人間の年収を500万円下げましょう、年収が500万円以下なら負債を負わせると良いでしょう。
Q. Facebookが外部サイト上に広告を出すかどうか
ずっと前からそういう噂はある。開始時期がいつなのかってのは具体的な話は出てないはず。利用規約、データ利用ポリシーの中で触れてるので、改定のタイミングで噂になってるのだろう。
外部サイト上の広告に写真とプロフィール使っていいかの設定は、ずっと前からある。新たにできてると思ってる奴は、Facebookの設定を網羅的に見たことがないのだろう。いつの間にかできている、と言ってる人もろくに見てない。この設定はかなり前からある。
少なくとも2011年8月以前から存在している。ソーシャルメディアコンサルタント的な仕事をしている人がこの設定の存在について今まで知らなかったのだとしたら、その人間は無知で無能なクズですので、そのような人間に仕事を与えてはいけません、今すぐ縁を切りましょう。
http://twigstechtips.blogspot.com/2011/07/facebook-ignoring-privacy-settings-for.html
Q. FacebookがAdsense的なサービスを始めるとした場合の懸念は何か?
パターンA: Facebook自身が、facebook.comドメインを使って広告ネットワークを展開するケース
個人特定できる状態で外部履歴を使うことにならないか、という点。これについては、広告目的のプロフィール生成に外部履歴使わないということがFAQに書かれてる。匿名の履歴を広告品質全般の改善に使う可能性があるとも書かれている。これは今までと同じで変わらない。
何が問題になるかというと、今までは「Facebook内に配信される広告」はユーザープロフィールを元に配信された広告だということを知っていればよかった。広告をクリックした時にユーザー属性が広告主に伝わる可能性がある、と、Facebook内に関してのみ注意を払っていればよかった。外部サイト上でもSNSのプロフィールを使ったターゲット設定がされた広告が配信される、のであれば「これはFacebookの属性情報使った広告ですよ」と明示しないといけないだろう。「どのような条件で出されている広告なのか」がユーザーから認識出来なければ、広告をクリックした際に、訪問先のサイトにどういった属性情報が伝わるのかが分からなくなってしまう。
パターンB: 外部の広告ネットワークと提携するケース
次に、第三者の広告ネットワークに対して、likeボタンの設置、興味を持っている友人の一覧を許可する場合。これはiframe使って第三者にユーザー情報渡さなくても出来る。ただし「Facebookが」ユーザーに対してどんな広告が配信されたのかを知りうる状況になる。likeボタンを使ったトラッキングしませんというルールが守られると信じるのであれば影響はないというか今までと大差がない。
さて、いずれにせよ「友人に対して配信される広告に自分のアイコンを使っていいのかという許可・拒否設定」は、気分の問題でしかない。それ以上の意味をもたらしてはいけない。不用意にスクリーンキャプチャを撮られて自分のアイコンが露出する可能性が上がるぐらいしかリスクが浮かばない。
Googleに外部サイト及びAdsenseに対して+1ボタンと友人を表示するのかどうかの設定(https://plus.google.com/+1/personalization/ )があるのは、DoubleClick cookieと、Googleのcookieを限定的とはいえ、連携するための設定だからだ。Adsenseを表示する際に、同時にgoogle.comのcookieを使ったコンテンツをロードすることになるからだ。
- GoogleはGoogleにログインしているユーザー自身が、広告に対してgoogleのログイン情報を連携させていいのか、という設定を選べるようにしてる。プライバシーリスクがあるから。
- Facebookは自分の写真が使われて平気かどうかの設定を選べるようにしている。
一見似ているけども、意味合いもリスクも違う。Facebookがユーザーを騙しているというつもりはないが、これは「ユーザーに対して自分の情報の公開範囲がきちんとコントロールできるかのような錯覚」を与えてしまう分、タチが悪い。
プライバシーを気にする人にとって本当に大事なことは「自分の属性情報を使ってターゲット設定された広告を拒否する設定があるか」であるのに、Facebookには、その設定が存在してなくて、自分のプロフィール画像を使って良いかの設定だけは以前からある。この設定はユーザープライバシーが漏洩する確率にほとんど影響しない。意味が無い。大した意味が無い設定があたかも何か重大な意味があるかのように騒がれてしまっている。
過去の事例
3月17日、毎日新聞掲載の記事。記事の掲載期限切れてるようなので丸ごと引用してるtumblrにリンクはる。
http://rapeandhoney.tumblr.com/post/19506965062
"グーグルもフェイスブックも、自分の情報の公開範囲や、広告などへの利用を止める設定ができる。"
この記事に対する自分の言及。ツッコミどころは他にもあるのだが、とりあえずFacebookの設定に関する箇所だけ取り上げる。
自己の情報の公開範囲をコントロールできますよ、というのは、広告のターゲティングに使われても構わない情報のコントロールが出来ますよ、とイコールではない。同列に並べるのは間違いだ。
まとめ
- 「広告に対してユーザーデータを使用して構わないか」という設定は、通常はこういうものではない。
- ユーザーに対してこの設定を選ばせる意味は殆ど無いし、意味が生じてしまうような(ユーザーデータが直接的に広告主や第三者に伝わってしまうような) 不適切な実装がされてはいけない。
- この設定をオフにすることで何が起きるかというと、ユーザーにとってのプライバシーリスクは、ほぼ全く変わらずに、単に広告のクリック率が下がるだけだ。
俺は本当にウンザリしているし、この件、このデマ、及び、意味を理解しないまま解釈をねじ曲げて拡散した人々を、心の底から馬鹿にしている、軽蔑している。iframeでどうとか、same origin policyがどうとか、そんなことは世間一般大多数の人間は知らなくていい。技術的なことを理解しているかどうかと無関係に、まともに日本語を読む能力が欠如している、悪意を持った歪んだ解釈をする、ソースを確認しないで拡散する。意味も理解しないまま、とりあえず設定をオフにしてみる。そのような人間の存在は、真にユーザーのプライバシーを守りたいと考えているユーザーや、事業者にとって脅威である。
本来必要であるのは「自分の属性情報を使ってターゲット設定された広告を拒否する設定があるか」だが、俺がFacebookの中の人だったらそんな設定を作りたくない。単に広告に使われて困るプロフィール情報は入力するなと言うだろう。「拒否する設定」を作ってしまうと、ちょっとデマを拡散されただけで「どの程度リスクがあるのか正確に判断できない人々」によって業績に深刻な影響をおよぼすことになるからだ。ユーザーの平均知能が低いままであれば本当に必要な選択肢が与えられないだろう。
最後にバカ発見器として機能している、この記事のブックマーク一覧に自分の知り合いの名前がなくて、本当によかった。大変喜ばしいことだ。本当によかった。id:kiyoheroとは縁を切ろうと思います。
http://b.hatena.ne.jp/entry?mode=more&url=http%3A%2F%2Fnanapi.jp%2F37983%2F
↧
Re: Do Not Trackがデフォルトでオンではだめなのか?
http://d.hatena.ne.jp/Rockridge/20120616/1339854043
例え話なので諸々いい加減な部分はあるけど私の考えは大体こんな感じです(例え話で理解したつもりになってはいけない)(ある程度技術的なことが理解できる人を対象とした記事です)
- -
遺伝子の突然変異か何かで、食品アレルギーに過敏になった未来、99%の人間が何らかの食品アレルギーを持っていて、食品によっては食べると実際に死んだりすることもある。まあ中には単なる食べ物の好き嫌いや、信仰上の理由もあったりするのだが、対外的にはあんまり区別が付かない感じだ。
以前の世の中は、そば粉アレルギーはそば屋に行かないとか、卵アレルギーはプリンを食べないとか、菜食主義者はステーキ屋に行かないとか、各々が自衛したり、食品メーカーやレストランがどういう食材を使っているのか明記したりしてきた。そうやって騙し騙しやってきたところ、いちいち確認するのが面倒だったり、海外のレストランに行って言葉が通じなかったり、うっかり言い忘れたりすると危険だから、技術的に解決しましょうという話になった。
そこでモジラっていう宗教団体が、食品アレルギーを浄化する御守の共通規格を提唱しました。本来は御守自体に食品を浄化するパワーなど何もなかったのですが、信心が深ければ店の人が配慮して何とかしてくれます。技術者たちは最初は「おいおいマジかよ」って思ってましたが、この世界でのモジラは国際的に強い影響力を持つ宗教団体ですし、意思表明の仕組みとしてはそれなりに機能するだろうと考えました。御守を自動検知してレストランのメニューを自動で変更する仕組みの開発などは、まだまだこれからですが、食品業界全体として取り組んでいくことが約束されました。
ちなみに、この世界でのマイクロソフトは、ユニクロとファッションセンターしまむらが合体した感じの強い影響力を持つ、衣料品販売団体です。マイクロソフトのそれなりに偉い人が「俺、卵アレルギーなんだよね、みんなもそうでしょ」といって、来季の主力商品に御守を編みこむことを発表しました。卵業界は反発しました。というか食品業界全体が反発しました。モジラも反発しました。
大事なことを言い忘れていたけど、この世界では大体の食品は無料で提供されていて、お金を取るのは一部の店だけだ。どういう仕組みでそうなっているのか人類の大半は知らない、けれど皆はそれが当たり前のことだと考えている。
- -
マイクロソフトはあほか、って言う人がいるのも、DNT自体がそもそもダメっていう人がいるのも分かると思う。DNTを有効にするだけでプライバシーが守られると考えてしまう人がいたら、そういう人は御守の効能を何か勘違いしているので止めたほうがいい。
どういうケースが危険なのか
- 実際に深刻な、そば粉アレルギーがある人が御守の効果を期待して、そば屋に入ってしまう(ウチはそんな御守対応してないし、そば粉抜きの蕎麦なんて作れねえよ!)
- 食品アレルギーがありますって言われても、具体的にどれがマズイのか分からない、ハンバーガー屋が卵小麦粉肉ピクルス抜きバーガーを提供して、まともなハンバーガーを食べるには高額料金が必要になる
- 御守付けてない人は何でも食べられる人なんだよね、と勘違いして、レストランが使っちゃマズイ食材を使うようになる
- ユニクロとファッションセンターしまむらが「皆のことを思ってダヨ!!」と言って食品業界のことなど知ったこっちゃない施策をとってしまう
- 信仰を理解していない人が強制的に御守を持たされることになる
- 御守自体完全にスルーしようぜって流れになって、モジラが信仰を失うことになる
以上です
↧
GoogleがSafariの設定を迂回してトラッキングしていたとされる件について(2)
http://d.hatena.ne.jp/mala/20120220/1329751480
の続き。書くべきことは大体既に書いてあったので、補足だけ書く。
Googleは制裁金2250万ドルを支払うことでFTCと和解した
まさか(まともに調査されれば)こんなことになるとは思わなかったので驚いた。異常な事態である。そしてGoogle側の主張を掲載しているメディアが殆ど無いのも異常な事態である。
2250万ドルもの制裁金(和解金)が課せられるのは、2009年に書かれたヘルプの記述が原因だという。
- 問題の記述 http://obamapacman.com/2012/02/google-willfully-bypasses-browser-privacy-settings/
- WSJが書いてるのも、google-opt-out-pluginのことである。http://online.wsj.com/article/SB10001424052970204880404577225380456599176.html
これはdoubleclick.netに対して恒久的にオプトアウトCookieをセットするためのブラウザ拡張機能で、オープンソースで公開されていて、見ればわかるけれど、積極的にアップデートされるようなプロジェクトではない。http://code.google.com/p/google-opt-out-plugin/source/list
2009年は Safari3,4のころで、正確に言えば、2009年時点でもこの記述は正確ではない。何らかのタイミングでファーストパーティとしてdoubleclick.netを訪問して、その際にトラッキングcookieがセットされる挙動があれば、引き続きトラッキングされる状況になる(広告のiframeを直接表示したら確実、広告クリック時にid cookieがセットされていたかは未確認)。そもそもこれは一般ユーザー向けのヘルプセンターにあるような文書ではない。技術ドキュメントに近いものだ。Google Chromeに対しても同等の案内が書かれている。
つまりGoogleは単に「この拡張機能がサポートされていないブラウザではサードパーティCookieをブロックする設定を使え」という案内をしていたところ
- http://www.google.com/ads/preferences/html/intl/ja/plugin/browsers.html#chrome
- http://cache.gyazo.com/2cac3dc2e18496512cd5e80d1bc688fc.png
Safariの仕様変更( https://bugs.webkit.org/show_bug.cgi?id=35824 )という外的な要因で、記述内容が不正確になったに過ぎない。「Googleがウソをついていた」のではなく、リリースノートに記載されないような、Safariの仕様変更で、ヘルプの記述が後から嘘になってしまったのだ。Googleはこの問題が起きた直後に、Safariに対しては「全てのCookieを許可」する設定にしていても、UserAgentでSafariを判別してテスト用のCookieすら発行しないという変更を行なっている。
- https://twitter.com/bulkneets/status/171556744504418304
- https://twitter.com/bulkneets/status/171557083420958720
google.comとdoubleclick.netのCookie連携の導入に関わらず、2010年のSafariの仕様変更によって、doubleclickのid cookieが多くのケースでセットされる状況になっていた。腫れ物に触れるように、Safariに対して一切の doubleclick.netドメインのCookieを設定しないようにしなければ、トラッキングCookieが自動で設定される状況になってしまった。
Safariだけ逆方向へと変更が進んだサードパーティCookieのポリシー
(ブラウザ側の立場で書くので以後Cookieの送信と書かれているのは、ブラウザからサーバーへのCookie送信のことを指す)
- Firefoxは、Firefox3において、サードパーティCookieの送信もブロックするという変更を行った 参考: http://d.hatena.ne.jp/mala/20111125/1322210819
- Google Chromeは about:flagsの設定で、サードパーティCookieの送信も無効化する設定が2011年1月頃に追加 http://www.thechromesource.com/block-all-third-party-cookies-appears-in-chrome-experiments/
- 後に、単に設定画面でサードパーティCookieをオフにするだけで、送信もブロックされるようになった http://code.google.com/p/chromium/issues/detail?id=98241http://code.google.com/p/chromium/issues/detail?id=113401
- Firefoxと同等に、これも「インターネットをブッ壊すので元に戻したほうが良いのでは」と書く人がいる https://groups.google.com/a/chromium.org/forum/?fromgroups#!topic/chromium-discuss/kfsb9V5IPcQ
この手の、インターネットが壊れる(Facebookが動かない)系の主張は、よく見られる。中には、デフォルトでブロックしつつ互換性のためにCookie受け入れポリシーを緩和してきた、Safariのポリシーを是とする人もいるだろう。サードパーティCookieが無効なら無効で、ポップアップウィンドウを開くなり、画面遷移するなりして、迂回手段をとって動作するWebサイトを作ることが出来るのだが、Webサイト側のバグではなく「ブラウザ側のバグなのでは」として報告されてしまうことが後を絶たない。ユーザーはそんなこと知ったこっちゃ無いので、単に動かないサイトが出てくると困るし、他のブラウザを使うようになってしまう。
Apple2006年の名言 http://web.archive.org/web/20070303025259/http://www.mac.com/web/ja/Tips/425954F3-DF73-4B9B-94AC-20EE4BDE374C.html
もしアップルが推奨するブラウザを使っていて機能しないサイトを見つけたら、 苦情を申し立てましょう。 そのサイトが、 Web 上でもっとも進化したものに対応できるブラウザでもうまく機能しないのはなぜなのか、 サイトオーナーに説明を求めるとよいでしょう。
Appleも当初はこんな具合に強気だったわけだが、実際のところ動作しないサイトが多くて他のブラウザに乗り換えられてしまうと困るので、WebKit側ではWebサイトとの互換性のための涙ぐましい努力、改善・改悪が行われてきた。他のブラウザにとっては、セキュリティホールとして判断されて修正された問題が、Safariに限っては仕様として維持され、Facebookが動かないだとか◯◯が動かないだとかそんな理由で、サードパーティCookieの受け入れポリシーが緩和されてきた。こういう時に他のブラウザはドメインごとにCookieの受け入れポリシーをカスタマイズ出来るようにしてきたのだが、Safariにはそれもない。他のブラウザが、サードパーティCookieのブロックと言った場合に「厳格なブロック」を行うポリシーを採用する中、デフォルトでサードパーティCookieをブロックするというポリシーを持っているSafariは、サードパーティCookieをブロックするという設定を維持したまま(ユーザーのプライバシーを守りますという体裁を保ったまま)、動作しないWebサイトを動作するようにするために、むしろCookieの受け入れポリシーを緩和してきた。
サードパーティCookieの送信をブロックしないのはセキュリティ上の問題でもある。クリックジャッキングの問題、JSONハイジャック、XSSやCSRFをこっそり踏まされても気付かない問題、特定サービスにログインしているかどうか判別できる問題。ブロックしているにも関わらず、サードパーティCookieの送信は行われるというポリシーは、これらの問題を全く解決しない。「送信をブロックしない」時点でセキュリティ上の意味も無く「既にCookieがセットされている場合は追加のCookieも受け入れ」というポリシーによって(例えば広告クリック時に「トラッキング目的ではない」Cookieをセットしたとしても)Safariは多くのトラッキングCookieも意図せずに受け入れてしまう状況になっている。(無論、サードパーティCookieの送信をブロックしない段階で、GoogleやFacebookやAmazonなど諸々の「既にログインしてるWebサイト」による外部埋め込みパーツにおけるアクセスログ取り扱いを信用していなければ、それはユーザーに取ってトラッキングCookieと同等の意味を持つことになる)
数年前までは、サードパーティCookieをブロックすることでトラッキングを拒否できます、というのがブラウザ開発者側の(あるいはWeb開発者、広告関係者の)全体的な総意であったが、今やサードパーティCookieに依存したWebサイト、サードパーティCookieをブロックすると動作しないWebサイトが多くなりすぎてしまった。彼らは「全てのCookieを受け入れるように」とブラウザの設定変更を促してしまう。だからユーザーはトラッキング拒否したくても、動かなくなるサイトが出てくると困るからサードパーティCookieを迂闊にオフに出来ない状況になってしまっている。なのでサードパーティCookieの設定とは独立して、技術的には何ら意味も持たない「ウェブをブッ壊すことが無い」純粋な意思表示の仕組みを用意しましょう(まあそれにCookieに限らずトラッキング手段はあるし)というのが、DoNotTrackの実態である。
サードパーティCookieの泥沼へようこそ。FTCが立ち入るには3年半は早かった、せめてDoNotTrackが機能するようになってからにしてくれ。(DoNotTrack普及後に)DoNotTrackを無視したのでGoogleに制裁金を、という話になるのであれば理解できる。SafariのCookie受け入れポリシーは、デフォルト設定を維持したままWebサイトとの互換性を解消するという無理難題タスクを課せられた結果、最早ポリシーとは呼べない魔窟となっており、あれはDoNotTrackでもなんでもない。SafariのCookie受け入れポリシーのことをDoNotTrackと呼ぶのは、今すぐやめろ。それと、サードパーティCookieオフにして動かない系の話の多くにFacebookが絡んでいるので、Facebookはこの争いに巻き込まれる資格がある。
なぜGoogleはこのような不名誉な和解を受け入れたのか
極めて不名誉な決定にもかかわらず、Googleは争わなかった。理由は容易に推測できる。
- 1. 多くの一般消費者は上記↑のような事情を、技術的背景を、一切理解出来ないだろうから
- 2. 深入りして調査されると、面倒くさいことになるのが目に見えているから
1については言わずもがな、問題は2である。そもそもこの問題の発端である、google.comとdoubleclick.net間のcookie連携について。doubleclick.netで提供されるGoogle Adsenseから、極めて限定的だが、google.comで提供されている +1の情報が参照されていることになるからだ。Adsenseに+1ボタンを表示するオプションは、現状Googleアカウント作成時にデフォルトでチェックされている。この程度の同意で、doubleclick.netで行われている匿名トラッキングとGoogleアカウントを、ガッツリ紐付けるようなことは、まず無いだろう。doubleclick.net側から参照できるGoogleのユーザー情報はどの程度のものか、きちんと個人を特定できないようになっているのか、_drt_ cookieの役割は何であるのか。それは、どうあがいてもサーバーサイドでの出来事であり、それが安全な方法で実装されているのかどうかは一般ユーザーからは観測することが出来ない。そういった対外的には観測不能なことについて、消費者の代わりに調査するのがFTCの本来の役割であろう。FTCは役割を果たさなかった。
まとめ
- ユーザーを欺く説明をしてきたのはむしろAppleの方であり、Google側の責任を追求するのは、極めて不公平なことである
- FTCは役割を果たさなかったし、技術音痴のマヌケである
- 技術系のライター、編集者はこの程度のことは調べて書け
- この決定を受けてFTCを支持している人間は、全員例外なく阿呆である
いちいち具体名とか挙げたくないけど、一部の技術者であったり、あるいは情報系の法学者だとか教授だとかそれなりの肩書きを持っている人間が、この決定をGoogleが何か悪いことをして制裁金を課せられたぐらいにしか思っていない。単なる前提知識不足では済まされない、メディアリテラシーの不足、インターネットに対する理解不足、本当に悲しむべき、深い深い断絶を感じている。どんだけ脳みそが単純化してるんだ、狂牛病にかかってないか疑ったほうがいい。
↧
↧
高木浩光さんへ、しっかりしてください
技術者としての良心に従ってこの記事を書きます。俺はセキュリティとプライバシーの人ではなく、JavaScriptとUIの人である。法律の勉強だって自分の生活と業務に関わりのある範囲でしかしないだろう。しかし少なくともJavaScriptやブラウザが絡むような部分については、確実に自分のほうが理解していると思っている。高木浩光さんが、あからさまに間違ったことを書いたり、おかしなことを書いていたりしても、徐々に誰も指摘しなくなってきたと思う。おかしなこと書いていたとしても、非技術者から見たときに「多少過激な物言いだけど、あの人は専門家だから言っていることは正論なのだろう」とか、あるいは技術者から見た時でも、専門分野が違えば間違ったことが書かれていても気付けないということもあるだろう。
もう自分には分からなくなっている。誰にでも検証できるような事実関係の間違い、あるいは、技術的な間違いが含まれていても、問答無用で拡散されていくのは何故なのか。気付くことが出来る人が実際に非常に少なくなっているのか、それとも、怖くて指摘できない人が多いのか。あるいは、気付いていてもそれを意図的に放置してしまっているのか。
2011年 10/20 GmailのスキャンとAdsenseの話
- https://twitter.com/HiromitsuTakagi/status/126885716553760769
- https://twitter.com/HiromitsuTakagi/status/126885948775608320
高木さんがハッキリと間違いでしたと書かないものだから、ずっと勘違いしたままの人もいるだろうし、実際に未だに引用している人もいるし「スコア:5, 参考になる」である。
- http://it.slashdot.jp/comments.pl?sid=572089&cid=2181664
- http://fnya.cocolog-nifty.com/blog/2012/06/yahoo-f98b.html
"許された理屈も知らないのに「抵抗感が無くなった」というのは、単に周りの人に合わせているだけではありませんか? "
"こういう輩(素人レベルで語る専門家風)は危険。海外で許されている事案を引き合いに、それが許されている技術的・法的特徴を知らずして、うわっつら感覚で「許すべき」とか語り始める。それに影響されて、海外で許されていない技術方式を日本でやってしまう事業者を生み出す。ミログもその例か。"
ここまで高圧的に堂々と言われたら「あれちょっと変だな」と思っていても、指摘できなくなってしまう。誰でも簡単に検証できることを、実際に検証する人が全然いない。
- https://twitter.com/bulkneets/status/126894003001102336
- https://twitter.com/bulkneets/status/126926338199269377
少なくとも、Gmailはここ最近、複数のメールを横断してその人にとって重要なメールを判定するという技術を導入して、それを広告にも応用するということをやった。この変更はGmailの画面で告知されたし、ニュースでも広く取り上げられた。単純なメール本文からのコンテンツマッチから、その人の興味を分析して広告を表示できるように変化した。つまり、メールアカウントに対して、その人にとって何が重要か、何に興味を持っているのかということを分析して保存するようになっている(ちなみにこの部分はオプトアウト出来る)
まさに自分が拡散した誤情報を元にして記事が書かれてしまったのに、それを訂正せずにリンクを張っている。この記事が書かれた段階で、間違いを把握しているはずで、page=7に対するリンクである。
Yahooメールがメールの内容に基づいたインタレストマッチを開始するという発表を受けて、この話が蒸し返され、Gmailはブラウザ側でメールのスキャンを行っているという勘違いをした発言がいくつか見られた(そもそもAdsenseの仕組みを勘違いしている)
その際のやり取りはここから辿れる https://twitter.com/tekusuke/status/217800848292589568
その結果、クロサカタツヤ氏が記事を書いてくれた http://diamond.jp/articles/-/21547
失望したのは、高木さんが以下の発言に星を付けていたことだ。
- https://twitter.com/Allmacanysoy/status/223598387155582976
- https://twitter.com/TakaNojiri/status/223628677521481728
そもそも高木さんが間違った認識のもとに人を罵倒したりしてて、その誤った認識が広まってしまっていたから、まずは正しい認識を広め、その上で世論を形成していかなければならないという話であるのに。
3/12 共産党のページのXSS
- https://twitter.com/HiromitsuTakagi/status/178488466265473026
- https://twitter.com/bulkneets/status/178489319533723648
まあこれは割とどうでもいいのだけど、はてなブックマークボタンのトラッキング無し版が貼られているかどうか、ソースを読んでるはずなのに気付かなかった(と思われる)。
3/18 medibaの話
オプトアウトがどういう仕組みで実現されているのかを調べている最中。
http://twilog.org/HiromitsuTakagi/date-120318
postMessageでトラッキングidを問答無用で親フレームに送ってしまうという、問題のある実装になっていた。高木さんはソースを(かなり詳しく)読んでいたのに、このことに気付かなかった。
はてなとTwitterの話
http://d.hatena.ne.jp/mala/20120524/1337839088
はてなに対しては「はてななんか倒産すればいいよ」とまで言ったのに、Twitterがトラッキング開始したときにはボイコットしなかった。
8/2 myappeeの話
https://twitter.com/HiromitsuTakagi/status/231045813353197571
"myappee に会員登録しようとすると、メールアドレス入力をfacebookから拾わせようとする。これでfacebookアカウントと紐付けようって寸法かな。"
何が「寸法かな」だ。ソース読めばどういう情報を取得しているのかは分かる http://cache.gyazo.com/eab496885723a4ac2537d743a9ee5c3a.png
これはFacebookのJavaScriptSDKを使って実装されていて、性別メールアドレス誕生日を取得するものだ。Facebookのidを取得して送信するコードは含まれていなかった。単に入力補完目的で使っている。高木さんは何のためにClient-side flowがあると思っているのか。サーバー側に不必要な情報を送ること無く、ブラウザ内で完結させることができるのが嬉しいのではないか。Facebookアカウントの情報取りたいんだったら、単に「Facebookアカウントをお持ちの方はFacebookアカウントでログイン出来ます」とやればいいだけだ。Facebookには本名を非公開にするような設定は無い。「Facebookでログイン」をやってしまえば、どうやったって、本名がついてまわってきてしまう。オプトはネット広告の会社である。必要なのは最適な広告配信のために必要な情報で、氏名など必要ないのだし、不必要な個人情報はリスクでしか無い。姓名判断で広告を出すわけではないし、マーケティングのための統計情報を作るのに氏名はいらない。
これは自分にとって、ゾッとする出来事だった。たとえプライバシーに配慮した方式で実装されていようとも、専門家がそれを汲み取ることが出来ないばかりか、むしろ逆方向の仮説を立てる。
高木さんほどの人が、この程度のことを察することが出来ないのは、おかしいと思った。あまりにもJavaScriptが読めないのであるか、それとも、意図的に多少おかしなことを書いて、どれぐらいRTされるのかとか、関係者が釣れないかとか、実験してるのではないかとすら思った。これを見たときに、もう本格的に何を言っても無駄だと思った。他社のサービス、どうせ終了するサービスであるし、こういったことを指摘したところで「と、見せかけて実はやっているのでは?」「メールアドレスで検索してFacebookアカウントを特定するのでは?」などと返されたら、自分はそんなことを知るわけがない。
8/11 Pathtraqの話
http://twilog.org/HiromitsuTakagi/date-120811
メッセサンオー事件に関して
https://twitter.com/HiromitsuTakagi/status/234138201185460225
"当時、原因として疑ったツールバー「Pathtraq」のサービス画面。URLにID・パスワードが含まれたアクセスがこのように記録されていた。"
大ウソだ。Pathtraqに記録されたURLにID・パスワードがは含まれていなかった。そもそも、これは事件が報道された日付であるし、Pathtraq経由で漏洩した疑いを持ったのであれば、日付をさかのぼった状態のスクリーンショットを保全するものではないのか。
https://twitter.com/bulkneets/status/234146798472663040
大体、そういった問題について指摘して、改善を求めたのは、他ならぬ高木さん自身ではないですか(2009年02月01日の日記)。
そもそも高木さんがRTした元発言の人は、Googleツールバー経由でURLが漏洩したものだと考えていた。管理画面のURLがクロールされるに至った原因は、そもそも解明されていなかったはずだ。憶測で語られていたことが、時間が経つと確定した事実かのように、人々の記憶に刷り込まれてしまう。デマの良くあるパターンだ。俺なら絶対そんな発言をRTしない。
願うこと
技術的な間違い、事実関係の誤認、それを元にして他者を攻撃しているもの。また、セキュリティを生業にしている人間であれば、パッと見わかりそうな問題をスルーして別の箇所に注目しているもの。プライバシー・セキュリティに配慮した結果こうなったと推測できるものを、逆方向の仮説を立ててしまうものがある。単にいくつか印象に残っているものをいくつか挙げたわけで、特に広告業界の関係者から見た場合や、高木さんが炎上させてきた企業の当事者からすれば、もっとあるだろう。
高木さんがTwitterでRTする発言の中には、事実関係について致命的な誤認をしていたり、あるいは、真っ当な技術者であればいくらなんでもそんな推測はしない、といったものが多く見られる。最初は「可能性がある」といって毎回気を使って言及されていたものが、徐々に「こんなことが行われているに違いない」「こんなことが行われるに違いない」と変移していく。特にCCCとTポイントに関する問題は、時系列で順を追ってみていけば、高木さんが何をしてきたのかが分かるだろう。実際には、ユーザーのプライバシーに配慮した方法で実装されていたり、他のサービスと大差がないものをより悪質と言ったり、A社がやる分には良いけどB社がやるのはダメだ、といった具合にねじ曲げてしまう。
本当に、この程度のことであれば、技術者であれば誰でも分かるでしょ、気付けるでしょ、といったレベルのことが指摘されなくなってしまった。なぜ間違いが指摘されなくなってしまっているのか。単に皆自分の仕事で忙しいとか、専門分野が違うので自信を持って書けないということもあるだろう。別の会社の内部事情なんて分からないのだし、所詮外部からは正確なことなんて分からない、口をはさむべきことじゃない、と考えてしまうのか。でも「いや、それってフツーに考えてそんなことしないですよ」ぐらいのことが言えなくなってしまった。(しないと思ってたことが実際には行われていてびっくり、ということももちろんあるだろうけど)
恐れ多くて誰も口に出せない、絡んでも得をしない。目立ちたくない。いわゆる高木信者と呼ばれるような人たちから、こいつはプライバシーを軽視する人間に違いないとレッテルを貼られ、集中砲火を浴び、そうやって当事者や中の人が情報発信できなくなってしまう。情報発信がされないことで、より一層、技術を理解する人と理解しない人の間での認識にズレが生じて、悪循環になってしまっている。
自分はクライアントサイドの人間だ。望めばどんなコードで何が動いているのか検証できる世界、望めば拒否できる、望めば完全にブロックできる、そういう世界を望むだろう。コードを読まず、あるいは読めずに憶測で批判する人間が大半であれば、あるいは少数でも異常に声が大きい人がそういう事をやってしまえば、実現しない。セキュリティ上の問題があったとしてもそれを見抜くことが出来ず、プライバシーに配慮した実装がされていようとも、それを汲み取ることが出来ず。違いを分からずに「今すぐ中止せよ、さもなくば悪徳企業」と言わんばかりに、圧力をかけている。説明すればするほど、露出を増やせば増やすほど、高木浩光に目をつけられ、炎上リスクだけが増加する。実際に実装に関わっているような技術者は批判を恐れて表に出なくなり「そもそも安全な実装にするにはどうすればいいの?」といったことが語られなくなっている。安全にする方法を考えられない人たちは、単に中止せよと言うだろう。
ネットの広告も、ユーザーの行動分析も、このままではユーザーから見て、より透明性が低く、検証がしにくく、何が行われているか分からない方法で同じことが行われてしまうだろう。何が行われているのか隠したほうが得になり、単に「必要な範囲で第三者に委託します」などと書かれ、裏側でアクセスログを丸投げするような、よりユーザーから制御しにくい方法で同じことが行われるようになってしまうだろう。正直者が得をしない、誠実であろうとすれば損をする。あなたはそういう世界を望んでいるのですか?
この人の持ち合わせている知識からすれば、あからさまに間違いである、デマである、誤解である、邪推である、単なる信用毀損情報である、そうやって判定できるはずのことをRTして拡散する。個々のユーザーに判断できるだけの知識を与えることなく、判断力を持たない無知なユーザーを煽動して、誤解に基づいた判断で世論を作りあげようとする。そういう様子を見てきて、もはや高木さんは「先生」と呼べるような人間では無くなったのだと思った。同じリストに入れられることを不快に思うようになった。「高木浩光の同類」といった扱いを受けてしまうのが我慢ならなくなった。一体いつからこんなことになってしまったのか。「あの人は昔からああだから」とか「十年前から変わらん」と人によっては言うだろう。いやしかし、ここ最近は特におかしい。人格や性格のことを、とやかく言うつもりはない。自分だって人のことを言えないだろう。もう本当に、この人は完全に放っておいたほうが良いのかな、十年変わらないものが今さら変わるわけが無いのかな、とも思う。
高木浩光を批判することで所属している企業が目をつけられて面倒くさくなるという可能性も多分にあるのだし、何も変わらないのであれば、純粋な、技術的な間違いの指摘であろうとも、もはや書く意味が無くなってしまう。もうみんな、あの人のこと放っておきましょうと主張することになってしまう。それでも、何でこんなことを書いているのかといえば、高木さんが技術に関しては誠実な人間だと思っているからだ。その部分に関しては、高木浩光に絶大な信頼を寄せている、寄せていたからだ。
高木さんへ
- 間違い、勘違いで書いたのであれば、より大きな声で訂正情報を流してください。
- 間違った情報を根拠にして、個人や企業を批判したのであれば、その部分についてはきちんと謝ってください。
- 真摯にセキュリティやプライバシーのことを考えている、技術者に対して、彼らの努力を無に帰してしまうような真似をしないでください。
- より良い未来を作ろうとしている技術者が軽蔑されるような世界を作らないでください。
- 正しい知識を広めようとしている人間に対して、レッテルを貼ったり、黙っていろなどと言わないでください。
単に誤解でした、勘違いでした、知識不足による間違いでした、で済む問題であれば、ちゃんと訂正すればいいのではないですか。妄想憶測で語られていたことや「可能性がある」といって語られていたことが、やがて既成事実化して語られてしまう。それはRTするより前に、まずは正しい事実を周知させることを優先すべきなのではないですか。もう目的を達成するためにはなりふり構わず、デマだろうが誹謗中傷だろうがお構いなしになっていませんか。自分も問題のある実装を批判したり、脆弱性に関する報告をすることがよくあります。しかし大抵の場合、必要以上に騒ぎ立てなくても、自分たちの作っているサービスに誇りを持っている人がいて、問題を認識してくれて、ちゃんと対応してくれます。たまに肉を奢ってくれたりもします。高木さんがこれからもずっと変わらないのであれば、あの人は技術者として信用できないのだと、間違いや思い込みで他人や企業を攻撃することがあるのだと、そうやって周囲の人間が接し方を変えていかねばならないのだと思う。ルール、法律、制度作りも何もかも、まずは正しい現状認識がなければ適切な世論形成が行わなくなってしまいます。新聞社の方、法律家の先生方、技術的な見識について間違いがないかどうか、複数の人から意見を聞くようにしてください。
もうずっと心のなかで引っかかっている。公開の場で主張すべきことを今まで主張してこなかったことを悔いている。目の前でいじめが行われているのを近くで見ているのにそれを制止できない、してこなかったような、本当にそういう心境になっている。
終わりに、面白おかしくネットバトル的な茶化し方をするのはやめてください。本当に深刻な問題だと考えています。
↧